Self-Hosting LLMs on Kubernetes: How LLMs and GPUs Work?
Series map
- Introduction
- How LLMs and GPUs work?
- GPU optimization
- Serving LLMs using vLLM
The Basics: How LLMs Store and Use Knowledge
Large Language Models (LLMs) are incredible tools, instantly turning complex queries into human-like text. But how does this magic actually happen on the hardware that powers it, the GPU (Graphics Processing Unit)? Before we get into hosting LLMs on Kubernetes, and how to optimize inference there, let’s first understand how actually GPUs work to enable LLMs to do their magic.
There are generally two main stages of an LLM; training and inference. The training happens on petabytes of data (mainly text for LLMs) and the inference is the process of an LLM generating a response based on the knowledge it learned during its training (stored in its weights/parameters).
Model weights are the fundamental components that store an AI model’s learned knowledge. During the training stage, a deep learning model figures out the relationships between all the examples in its training set and encodes these relationships into a series of model weights.
In the context of an LLM, a weight/parameter is a value the model can change independently as it learns, and the total number of parameters determines a model’s complexity. For example, Llama-3.2-1B has a size of 1.24B parameters 🤯. Let’s explain this concept using an example, The spam detector model.
Consider an AI model built to flag incoming emails as spam or not spam:
- During Training: The model is fed thousands of labeled emails and learns to recognize patterns like the presence of certain keywords or excessive use of exclamation marks.
- Encoding Knowledge: The model encodes these learned patterns into its weights, creating a complex set of rules to identify spam.
- During Inference: When a new, unseen email arrives, the model analyzes its characteristics and compares them to the patterns stored in its weights to make a prediction, such as assigning a 90% probability that the email is spam.
Now that we understand what model weights are, let’s explore how LLMs use these weights during inference—and why GPUs are essential to this process.
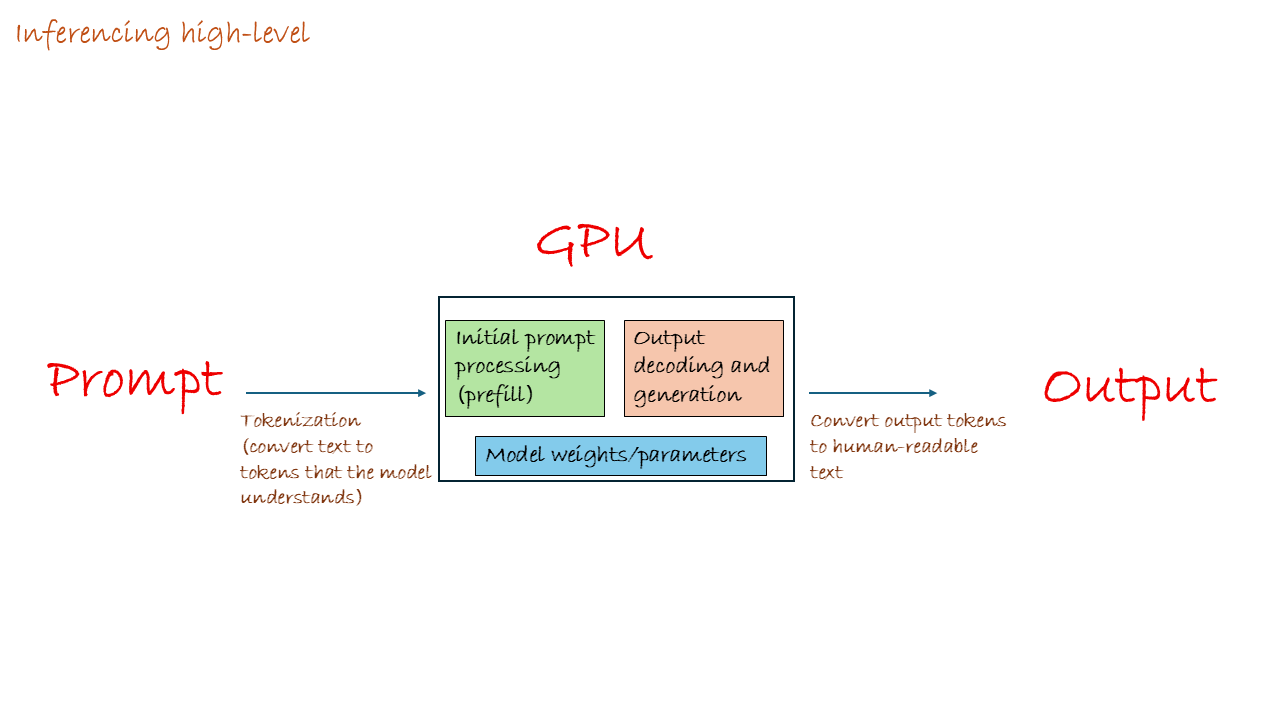
The GPU Engine: How LLM Inference Turns Your Prompt into a Reply
Part 1: LLMs 101 – The Prediction Machine
What an LLM Sees when you send your prompt
When you type a prompt, the LLM doesn’t see words. It sees tokens. A token is a chunk of text, it could be a whole word, a part of a word, or even just punctuation.
The token is not always a human word
- Example: The phrase “The brown fox jumps” might be broken into tokens like:
[The] [brown] [fox] [jumps]
Everything the LLM learned from its massive training data (trillions of tokens!) is stored as a colossal collection of numbers, called weights or parameters as we discussed earlier. In the case of LLM models, think of these weights as a giant, incredibly complex set of rules that governs how likely one token is to follow another.
How it Works: The Next Token Game
When you ask an LLM a question, its only job is to calculate the single most likely token that should come next.
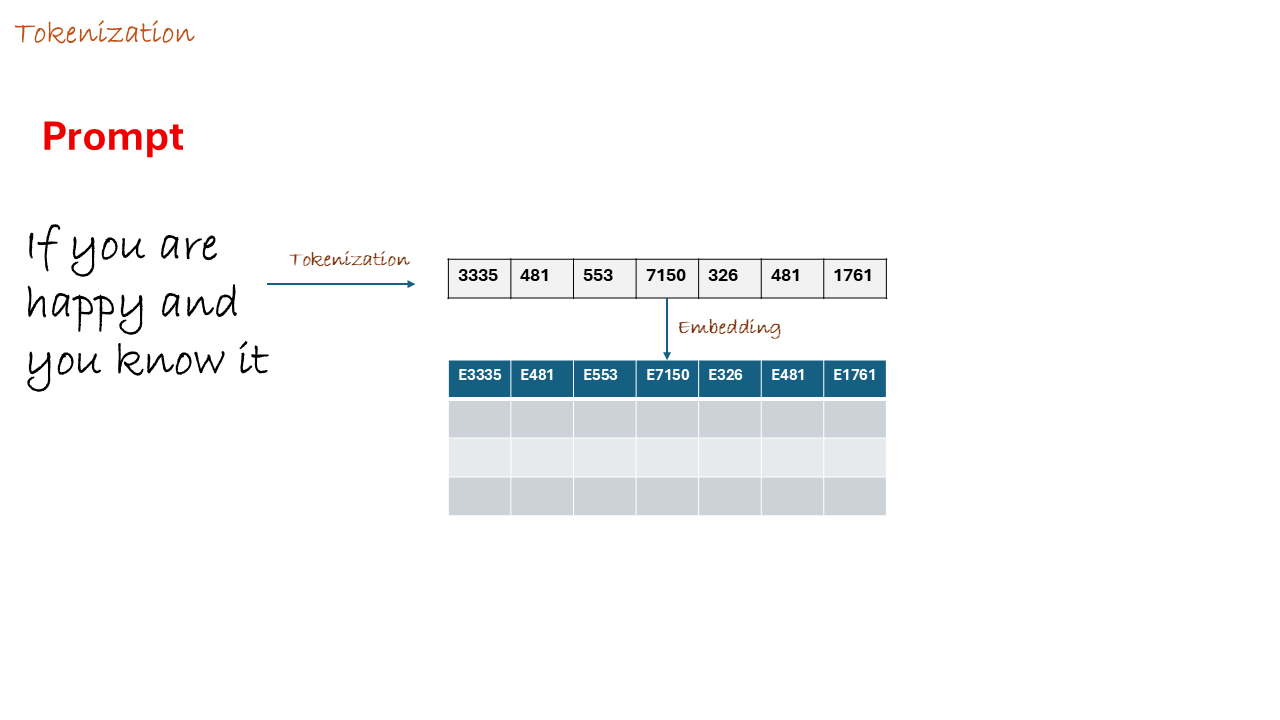
- Input: You type: “The capital of France is”
- Tokenization: The LLM converts your text into a sequence of token IDs (integers). You can see an example using tiktokenizer
- Embedding: Each token ID is converted into a high-dimensional vector (a list of numbers), and these vectors are arranged into an embedding matrix
- Processing: The LLM passes these embeddings through dozens of transformer layers (each layer is like a processing stage that refines understanding), performing massive matrix multiplications at each layer to understand context and relationships between tokens.
- Prediction: The final layer produces a probability score for every possible next token in its vocabulary (which can be over 50,000 possibilities!)
- Output: It ranks the options:
[Paris](99% likely),[Berlin](0.5% likely),[the](0.1% likely), etc. - Selection: It picks the winner:
Paris.
This process of generating a response from your input all the way to the final word—is called Inference.
Part 2: The GPU Enters the Ring
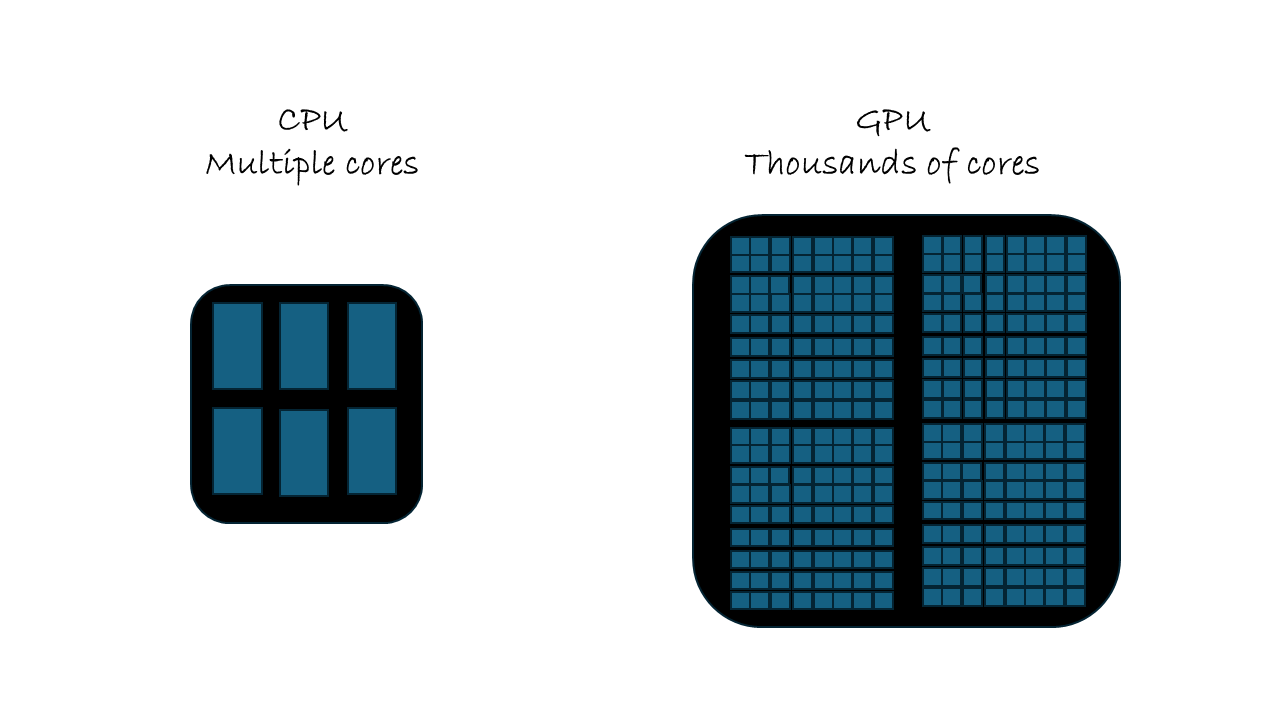
If an LLM’s job is to do one calculation after another, why do we need a Graphics Processing Unit (GPU) instead of a regular Central Processing Unit (CPU)?
The answer is Matrix Multiplication.
An LLM’s weights and your input tokens are all represented as giant grids of numbers called matrices. The core math that happens inside the LLM to figure out the next token is nothing but repeatedly multiplying these gigantic matrices together.
| CPU | GPU | |
|---|---|---|
| Core Count | 4-64 powerful cores | 10,000+ specialized cores |
| Parallelism | Limited parallel execution | Massive parallel execution |
| Best Use | Sequential logic and decision-making | Identical operations on large datasets |
| Why It Matters for LLMs | Handles preprocessing and coordination | Executes billions of simultaneous operations needed for matrix math |
The LLM’s matrix calculations are parallel, meaning you can break them into thousands of small, identical math problems and solve them all at the exact same time. The GPU, with its thousands of tiny processing cores, is specifically designed to do this kind of massive, concurrent math lightning-fast.
Part 3: The Token Generation Loop – The Iterative Dance
This is where the magic happens and where the GPU shows its value. Remember that an LLM only predicts one token at a time. This means generating an entire sentence is a continuous, iterative cycle.
Let’s see what happens step-by-step when you type a prompt and the LLM and GPU work together.
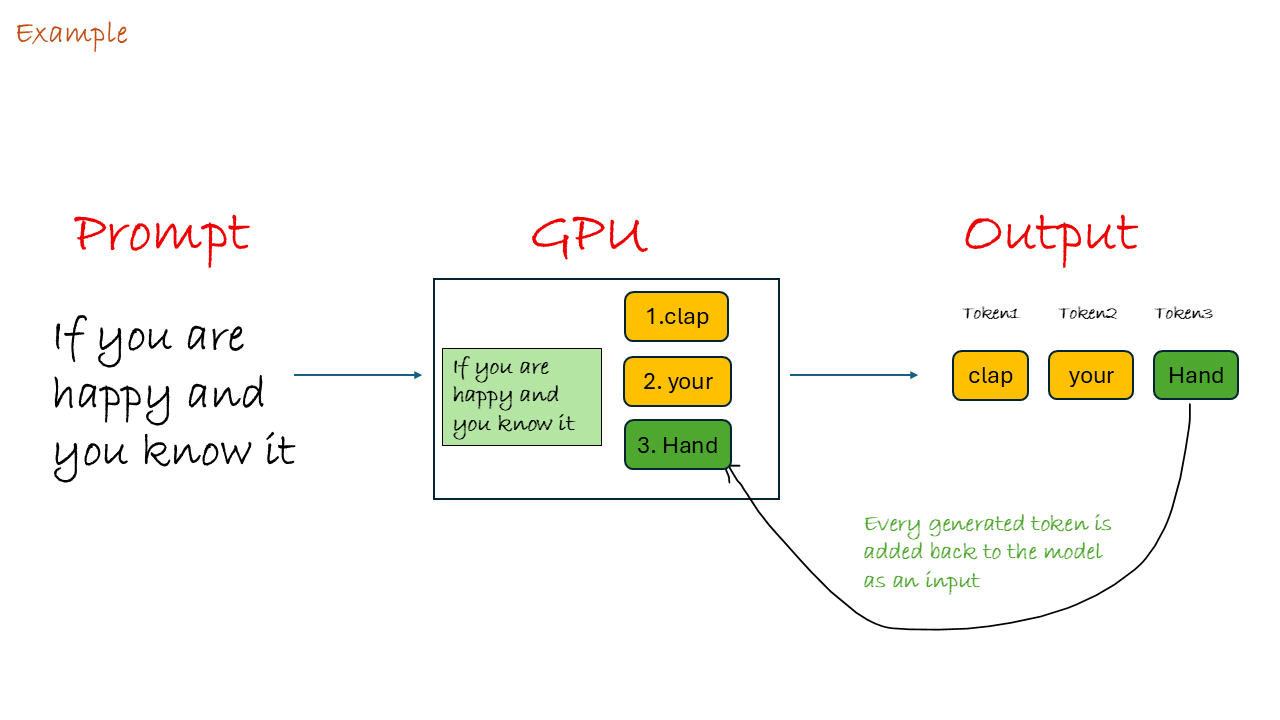
Input Prompt: “If you are happy and you know it”
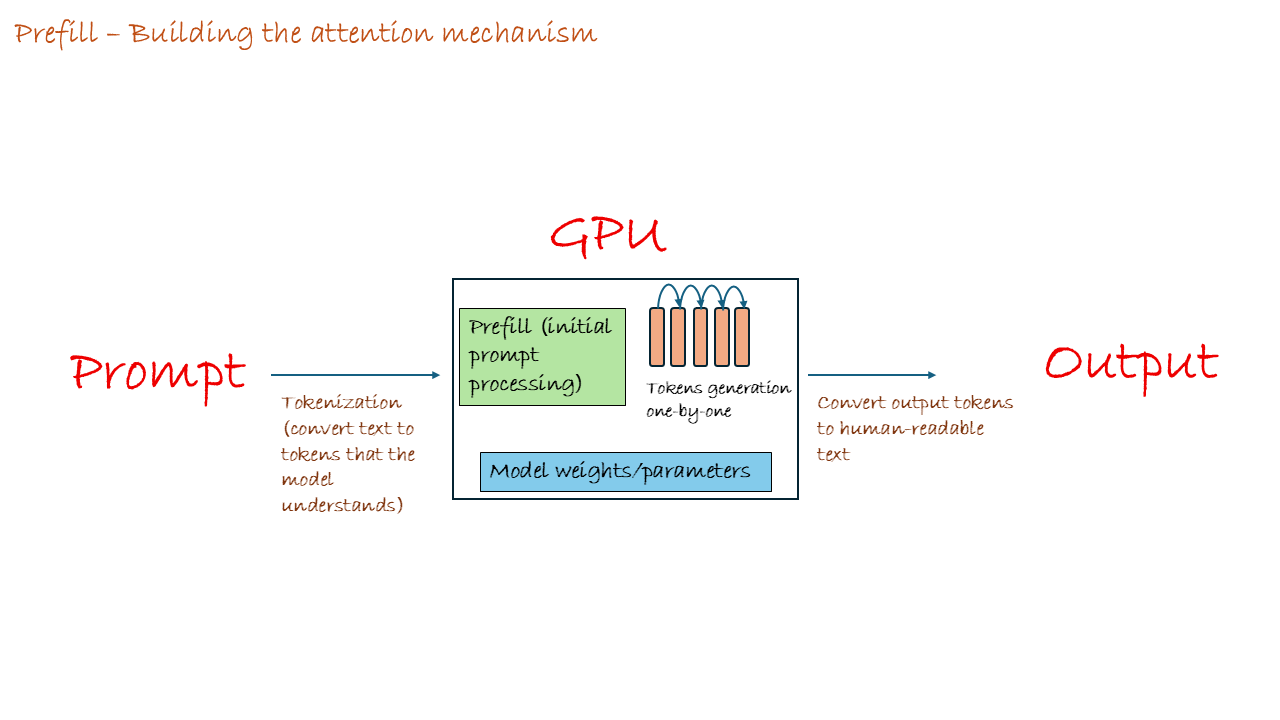
Step 1: Prefill (The Initial Kick-off)
The entire input prompt ([If] [you] [are] [happy] [and] [you] [know] [it]) is sent to the GPU.
- GPU’s Job: It performs an enormous amount of matrix multiplication for the whole sequence to understand the context and get ready to predict the first new token. This is a big, computationally heavy step, and the GPU is running full tilt.
- Result: The LLM predicts the next most likely token is
clap.
This is usually the most time-intensive task the GPU does, that’s why the LLM takes more time to spit out its first response then after that its very snappy.
What is the KV Cache?
Before we dive into the next step, let’s understand a critical optimization that makes LLM inference fast: the KV Cache (Key-Value Cache).
During the Prefill stage, the GPU doesn’t just predict the first token, it also computes and stores special mathematical representations called Key (K) and Value (V) vectors for every token in your input prompt. These vectors capture the meaning and context of each token.
Think of the KV Cache as the GPU’s working memory:
- Without KV Cache: Every time the LLM generates a new token, it would have to re-process the entire conversation history from scratch—an incredibly wasteful and slow process.
- With KV Cache: The GPU stores these K and V vectors in its ultra-fast memory (VRAM). When generating the next token, it only needs to compute the K and V vectors for the newly generated token and reuse all the previously cached K and V vectors.
The KV Cache grows with each new token generated, which is why GPU memory (VRAM) is such a critical resource in LLM inference. We’ll see this optimization in action in the next step. Here is a very simple video to explain the idea.
Step 2: The Loop Begins (Token #1)
The LLM selects clap and adds it to the sequence.
- Current Context: “If you are happy and you know it clap”
- GPU’s Job: The GPU now performs another set of matrix multiplications, but this time, it needs to predict the next token based on the entire context (If you are happy and you know it clap). However, thanks to the KV Cache, it doesn’t reprocess everything, it only computes the vectors for the new token
clapand combines them with the cached results from the original prompt.
Optimization Note (KV Cache): Crucially, the GPU is smart. It has already cached the calculations for “If you are happy and you know it” in its VRAM so it just retrieves it. It only performs the complex, full-sequence math on the new token (
your) and combines it with the saved results. This dramatically speeds up the loop!
- Result: The LLM predicts the next most likely token is
your.
Step 3: The Loop Continues (Token #2)
The LLM selects your and adds it to the sequence.
- Current Context: “If you are happy and you know it, clap your”
- GPU’s Job: It updates the KV Cache with the new calculations for
yourand computes the next token prediction. This step is repeated thousands of times a second. - Result: The LLM predicts
hands.
This loop, calculate, select, append, calculate again, repeats until the LLM generates a special <stop> token or reaches a set length. This is why faster GPUs mean lower Inter-Token Latency (the time between one word appearing and the next).
Laying the Foundation
We’ve covered the essentials: LLMs generate text one token at a time through matrix multiplication, GPUs excel at this with thousands of parallel cores, and the KV Cache is the critical optimization that keeps inference fast by avoiding redundant calculations.
But understanding how it works is just the beginning. The real challenge comes when you’re running production workloads: How do you optimize GPU utilization?
In the next post, we’ll tackle GPU optimization techniques that make LLM inference efficient and cost-effective on Kubernetes.
Share on:You May Also Like

Self-Hosting LLMs on Kubernetes: Intro
Series map Introduction How LLMs and GPUs work? GPU optimization …

Level Up your workflows with GitHub Copilot’s custom chat modes
GitHub Copilot has evolved far beyond just completing lines of code — …

Tips - Pre-check your AI models quotas using AZD
When deploying Azure OpenAI models, you usually have to first do some …