CI/CD evaluation of Large Language Models using OpenEvals
Reliability of Large Language Models: Why continuous Evaluation Matters?
Large Language Models (LLMs) like GPT-4, Claude, and Gemini have become the engines powering everything from chatbots to advanced research tools. But as these models grow more capable, one question looms larger than ever: How do we really know they work as intended?
Evaluating LLMs isn’t just about measuring accuracy on benchmark datasets. It’s about understanding how they reason, whether they produce reliable outputs, and how their performance varies across different tasks, user prompts, and languages. Robust evaluation frameworks help us compare models, detect biases, uncover hidden limitations, and build trust in AI systems. Instead of relying on one-time benchmark tests, teams are increasingly embedding LLM evaluation into their development workflows. By integrating evaluations directly into CI/CD pipelines, especially with tools like GitHub Actions, developers can automatically validate model performance every time new prompts, data, or model configurations are changed. This approach makes it possible to catch regressions, monitor bias, and track quality over time without manual intervention. Continuous evaluation pipelines help ensure that LLM-powered applications stay reliable, up-to-date, and aligned with user expectations as they evolve.
In this post, we’ll setup a very simple pipeline using an open-source evaluation framework from LangChain (OpenEvals) to evaluate our LLM whenever a change is introduced to our model or system prompt. Whether you’re building AI products or maintaining enterprise-grade workflows, understanding how to automate LLM evaluation will give you a powerful toolkit for deploying models you can trust.
Folder structure
We will create a very basic folder structure for this project to host our infrastructure, CI/CD pipeline, LLM data and evaluation script.
├───.github
│ └───workflows
│ eval.yml
│
├───data
│ llm.json
│
├───infra
│ main.bicep
│ main.bicepparam
│
└───src
evaluation.py
requirements.txt
- .github: will host the GitHub action which will start our evaluation process on any pull request submitted to specific files
- data:: will host different data for our LLM, like system prompt, user prompt (for demo purposes), evaluation thresholds and reference output for our evaluator to use.
- infra: will host our Bicep code deploying our infrastructure
- src: will host our evaluation logic written in Python and our Python dependencies file
requirements.txt
Building our Infrastructure
Our first step will be deploying the infrastructure on Azure to stand up an Azure OpenAI instance where we will host our LLMs. We will deploy a user-assigned managed identity which we will use to create a federated identity credential to be able to securely authenticate and deploy resources to Azure.
targetScope = 'managementGroup'
param location string = 'swedencentral'
param infraResourceGroupName string = 'rg-ai-dev-${namingPrefix}'
param namingPrefix string = take(newGuid(),5)
param models array
param githubOrganization string
param githubRepo string
param subscriptionId string
module infraResourceGroup 'br/public:avm/res/resources/resource-group:0.4.1' = {
name: 'deployment-Infra-resourceGroup'
scope: subscription(subscriptionId)
params: {
name: infraResourceGroupName
location: location
}
}
module userAssignedIdentity 'br/public:avm/res/managed-identity/user-assigned-identity:0.4.0' = {
scope: resourceGroup(subscriptionId,infraResourceGroupName)
dependsOn: [
infraResourceGroup
]
name: 'deployment-user-assigned-identity'
params: {
name: 'msi-ai-001'
federatedIdentityCredentials: [
{
name: 'github_OIDC'
audiences: [
'api://AzureADTokenExchange'
]
issuer: 'https://token.actions.githubusercontent.com'
subject: 'repo:${githubOrganization}/${githubRepo}:pull_request'
}
]
}
}
module umiRoleAssignment 'br/public:avm/ptn/authorization/role-assignment:0.2.2' = {
params: {
principalId: userAssignedIdentity.outputs.principalId
subscriptionId: subscriptionId
resourceGroupName: infraResourceGroupName
principalType: 'ServicePrincipal'
roleDefinitionIdOrName: 'Contributor'
}
}
module azureOpenAI 'br/public:avm/res/cognitive-services/account:0.11.0' = {
name: 'deployment-azure-openai'
scope: resourceGroup(subscriptionId,infraResourceGroupName)
dependsOn: [
infraResourceGroup
]
params: {
name: 'openai${take(uniqueString(deployment().name,location,namingPrefix),5)}'
kind: 'OpenAI'
location: location
customSubDomainName: 'openai-${take(uniqueString(deployment().name,location,namingPrefix),5)}'
publicNetworkAccess: 'Enabled'
disableLocalAuth: false
networkAcls: {
defaultAction: 'Allow'
ipRules: []
virtualNetworkRules: []
}
sku: 'S0'
deployments: models
managedIdentities: {
systemAssigned: true
}
roleAssignments:[
{
principalId: deployer().objectId
roleDefinitionIdOrName: 'a001fd3d-188f-4b5d-821b-7da978bf7442'
description: 'Cognitive Services Account Contributor'
principalType: 'User'
}
{
principalId: userAssignedIdentity.outputs.principalId
roleDefinitionIdOrName: 'a001fd3d-188f-4b5d-821b-7da978bf7442'
description: 'Cognitive Services Account Contributor'
principalType: 'ServicePrincipal'
}
]
}
}
output aiendpoint string = azureOpenAI.outputs.endpoint
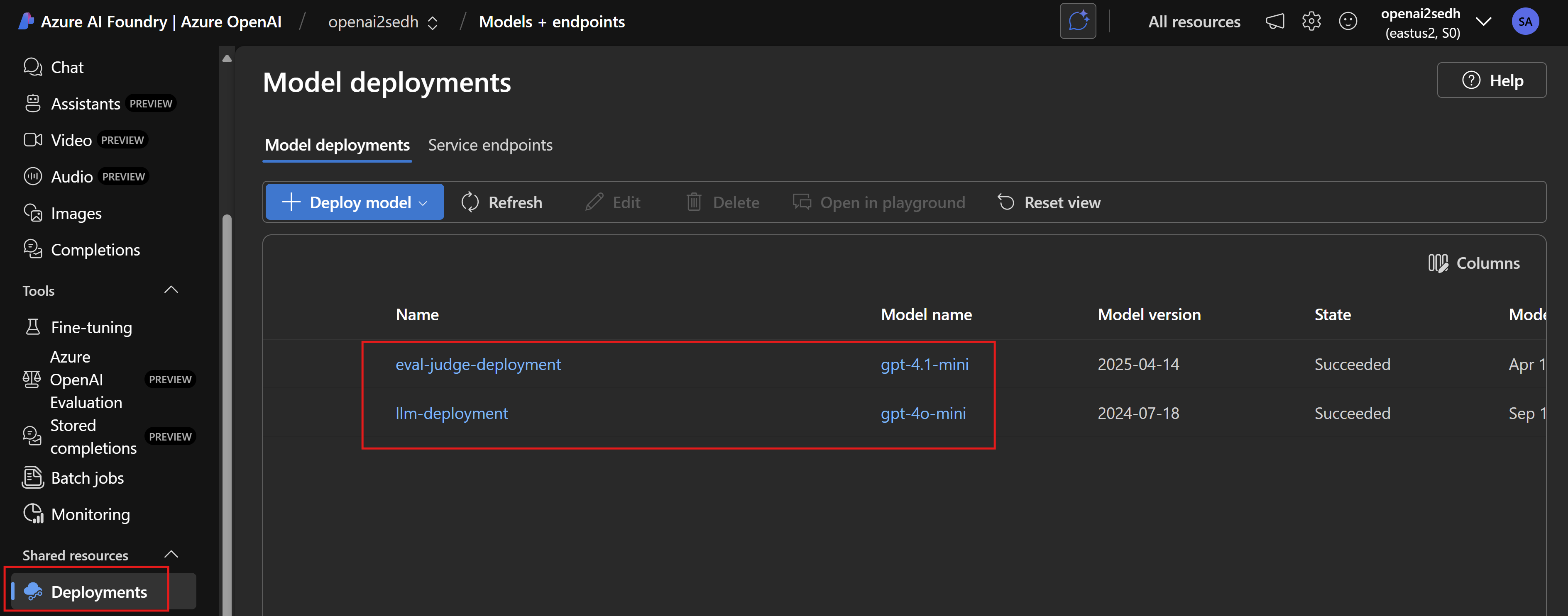
We will also provide a parameters file with the models we want to deploy to the Azure OpenAI instance. In this example, we will have two deployments:
- llm-deployment: will host our main model which our application will use. This is the model we need to perform evaluation for and it can change by time.
- eval-judge-deployment: will host our judge model. This is the model we will use to evaluate our main model’s output.
using './main.bicep'
param location = 'eastus2'
param githubOrganization = 'sebassem'
param githubRepo = 'langchain-evals'
param subscriptionId = ''
param models = [
{
name: 'llm-deployment'
model: {
format: 'OpenAI'
name: 'gpt-4o-mini'
version: '2024-07-18'
}
sku: {
capacity: 40
name: 'GlobalStandard'
}
}
{
name: 'eval-judge-deployment'
model: {
format: 'OpenAI'
name: 'gpt-4.1-mini'
version: '2025-04-14'
}
sku: {
capacity: 40
name: 'GlobalStandard'
}
}
]
Looking into the AI Foundry portal, we can see our two models have been deployed successfully.
Configuring GitHub OIDC for secure deployment to Azure
We can also see the federated credential created for our user-assigned managed identity.
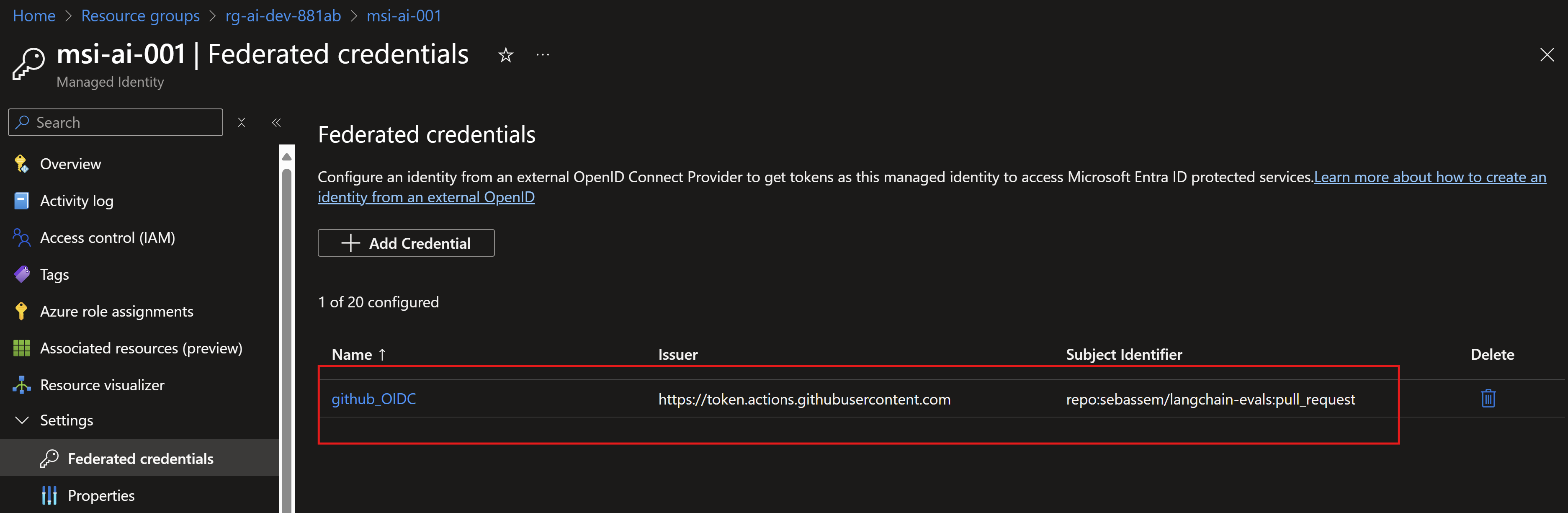
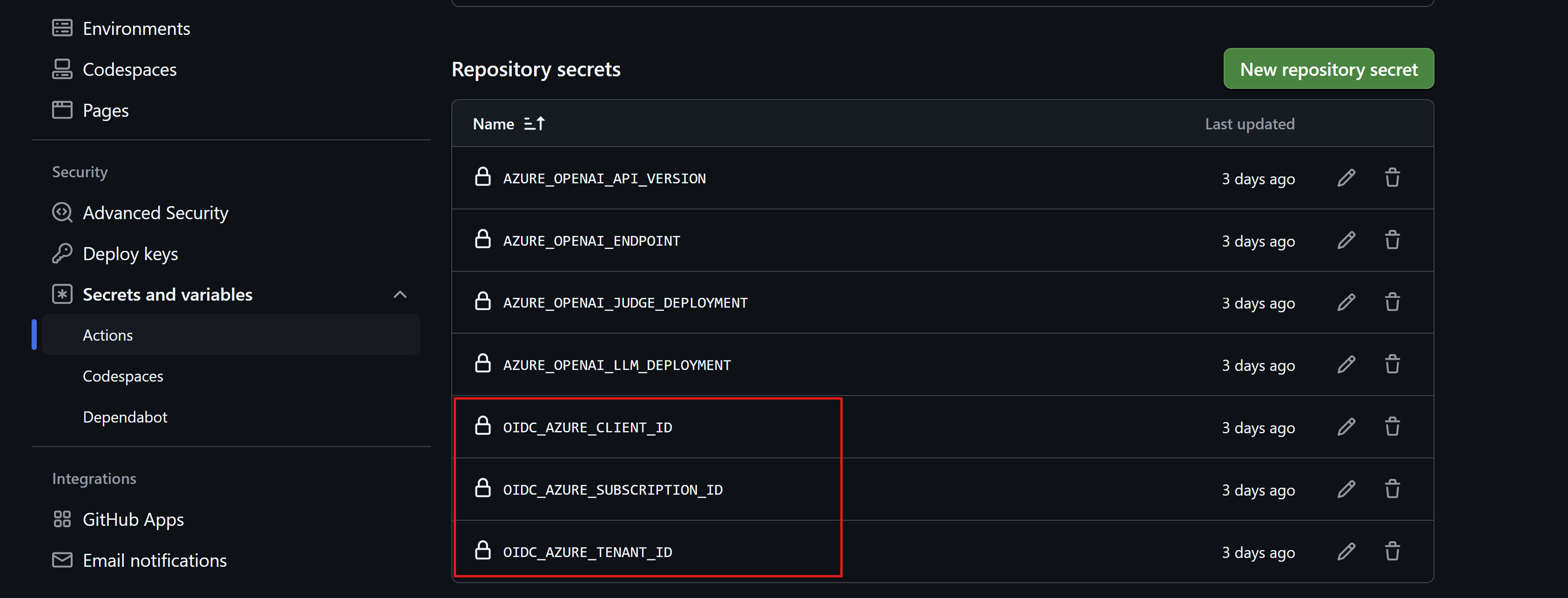
For the OIDC flow to work, we need to add some GitHub secrets to our repository for the OIDC authentication to work.
Coding our evaluation process
NOTE: There are multiple evaluation frameworks out there but I chose OpenEvals from LangChain as its easy to configure and works with most LLMs out there. I tried the AI Foundry evaluation GitHub Action but for some reason at the time of this post, it seemed broken.
Our evaluation script will do the following:
- Import all needed libraries
- Load the environment variables which will have Azure OpenAI deployment names, endpoints,..etc
- Load the system prompt, reference output, defined thresholds for each evaluator from a JSON file
- Securely connect to Azure using the user-assigned managed identity
- Initialize our two Chat models
- Initialize 3 evaluators using the judge model we deployed into Azure OpenAI
- Run the evaluators against the inputs (system and user prompts, reference outputs,…etc)
- Evaluate the evaluators outputs and calculate if its below or above the thresholds
- Return the results to the GitHub action for processing and output into GitHub job summaries in a readable format
The OpenEvals framework has the follow set of built-in evaluators that we will use, you can also build a custom one if needed and also test your RAG pipeline:
- Correctness
- Conciseness
- Hallucination
NOTE: The full code will be published on GitHub as in this post, I will only tackle the most important pieces
Let’s first start by creating the requirements.txt with all the required libraries to be installed. You can see we add the azure-identity library which we will use to connect to our Azure OpenAI service using a managed identity.
# Core dependencies
python-dotenv>=1.0.0
pydantic>=2.0.0
# LangChain dependencies
langchain-openai>=0.1.0
# OpenAI Evaluation dependencies
openevals
#azure identity
azure-identity>=1.10.0
We will also create a json file with all the input data we need in the script so its easier to change/update and avoid hardcoding values.
[
{
"name": "system_prompt",
"role": "system",
"prompt": "You are a helpful assistant that answers questions around AI and machine learning."
},
{
"name": "user_prompt",
"role": "user",
"prompt": "What's the difference between supervised and unsupervised learning in machine learning?"
},
{
"name": "reference_outputs",
"content": "Supervised learning involves training a model on labeled data, where each input has a corresponding correct output. The model learns to map inputs to outputs. Example: A spam email classifier trained on emails labeled as spam or not spam. Unsupervised learning uses data without labels. The model tries to identify patterns or structures in the data. Example: Customer segmentation using clustering algorithms like K-Means, where the model groups customers based on purchasing behavior without predefined categories."
},
{
"name": "evaluation_thresholds",
"content": {
"conciseness": 0.7,
"correctness": 0.8,
"hallucination": 0.7
}
}
]
Next, we will start coding the evaluation python script, starting with the import statements where we will import the OpenEvals evaluators and use the llm-as-judge approach.
import os
import json
from dotenv import load_dotenv
from pydantic import SecretStr
from langchain_openai import AzureChatOpenAI
from openevals.llm import create_llm_as_judge
from openevals.prompts import CONCISENESS_PROMPT
from openevals.prompts import CORRECTNESS_PROMPT
from openevals.prompts import HALLUCINATION_PROMPT
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
We then need to load all the data from the json file to be used in the script.
# Load system prompt from JSON file
def load_system_prompt():
json_file_path = os.path.join(os.path.dirname(__file__), "..", "data", "llm.json")
with open(json_file_path, 'r') as file:
data = json.load(file)
# Find the system prompt in the array
for item in data:
if item["name"] == "system_prompt":
return {
"role": item["role"],
"content": item["prompt"]
}
raise ValueError("System prompt not found in llm.json")
# Load user prompt from JSON file
def load_user_prompt():
json_file_path = os.path.join(os.path.dirname(__file__), "..", "data", "llm.json")
with open(json_file_path, 'r') as file:
data = json.load(file)
for item in data:
if item["name"] == "user_prompt":
return {
"role": item["role"],
"content": item["prompt"]
}
raise ValueError("User prompt not found in llm.json")
# Load reference outputs from JSON file
def load_reference_outputs():
json_file_path = os.path.join(os.path.dirname(__file__), "..", "data", "llm.json")
with open(json_file_path, 'r') as file:
data = json.load(file)
for item in data:
if item["name"] == "reference_outputs":
return item["content"]
raise ValueError("Reference outputs not found in llm.json")
Next, we need to initialize our LLM models using LangChain. We will use the llm-deployment with gpt-4o-mini as our main model and eval-judge-deployment with gpt-4.1-mini as our judge model. The connection will be using Entra ID instead of API keys for better security.
# Create the LLM ChatOpenAI model
model = AzureChatOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_deployment=os.getenv("AZURE_OPENAI_LLM_DEPLOYMENT"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
openai_api_type="azure_ad",
azure_ad_token_provider=token_provider,
max_tokens=300,
temperature=0.5
)
# Create the judge ChatOpenAI model
judge_model = AzureChatOpenAI(
azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_deployment=os.getenv("AZURE_OPENAI_JUDGE_DEPLOYMENT"),
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
openai_api_type="azure_ad",
azure_ad_token_provider=token_provider,
max_tokens=300,
temperature=0.5
)
We will also need to initialize our built-in evaluators and pass the above judge_model as the judge parameter.
conciseness_evaluator = create_llm_as_judge(
prompt=CONCISENESS_PROMPT,
feedback_key="correctness",
judge=judge_model,
continuous=True
)
correctness_evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
feedback_key="correctness",
judge=judge_model,
continuous=True
)
hallucination_evaluator = create_llm_as_judge(
prompt=HALLUCINATION_PROMPT,
feedback_key="hallucination",
judge=judge_model,
continuous=True
)
Now, if we try to run the code to query the LLM with the question ‘What’s the difference between supervised and unsupervised learning in machine learning?’, we get the following response which is very verbose with lots of unnecessary information that can affect our users’ experience and the overall cost of the AI system we are building.
### Supervised Learning:
1. **Labeled Data**: Supervised learning uses labeled datasets, meaning that each training example is paired with an output label. For instance, in a dataset for image classification, each image would have a corresponding label that indicates what is depicted in the image.
2. **Objective**: The main goal is to learn a mapping from inputs (features) to outputs (labels) so that the model can predict the output for new, unseen data. This is often done through regression (predicting continuous values) or classification (predicting discrete categories).
3. **Examples**: Common algorithms include linear regression, logistic regression, decision trees, support vector machines, and neural networks.
4. **Evaluation**: The performance of a supervised learning model can be evaluated using metrics such as accuracy, precision, recall, F1 score, and mean squared error, depending on the task.
### Unsupervised Learning:
1. **Unlabeled Data**: In unsupervised learning, the model is trained on data that does not have labeled outputs. The algorithm tries to learn the underlying structure or distribution of the data without any specific guidance on what the output should be.
Now if we try to run one of the evaluators like the conciseness one, we can see that it provides a score and some comments on how the model response is very verbose.
outputs = result.content
conciseness_evaluator = create_llm_as_judge(
prompt=CONCISENESS_PROMPT,
feedback_key="correctness",
judge=judge_model,
continuous=True
)
conciseness_eval_result = conciseness_evaluator(
inputs=messages,
outputs=outputs
)
print("Conciseness evaluation result:", conciseness_eval_result)
Evaluator output:
{
'key': 'correctness',
'score': 0.2,
'comment': "The response provides a detailed explanation of the differences between supervised and unsupervised learning, including definitions, data requirements, objectives, algorithms, and applications for supervised learning, and starts to explain unsupervised learning similarly. However, the answer is excessively long and includes unnecessary context, background information, and explanations that were not explicitly requested. It also uses introductory phrases and includes multiple points and examples that go beyond the minimum necessary to answer the question concisely. Therefore, it does not meet the rubric's criteria for conciseness, which requires only the exact information requested with minimal words and no extraneous details or explanations. Thus, the score should be: 0.2.",
'metadata': None
}
Now, let’s take what we achieved so far, build the GitHub action, incorporate all three evaluators and output the result into the job summary.
Building the evaluation pipeline
First step is to define the environment variables that our code expects, those are added as GitHub repository secrets already after we deployed the infrastructure.
env:
AZURE_OPENAI_ENDPOINT: ${{ secrets.AZURE_OPENAI_ENDPOINT }}
AZURE_OPENAI_LLM_DEPLOYMENT: ${{ secrets.AZURE_OPENAI_LLM_DEPLOYMENT }}
AZURE_OPENAI_JUDGE_DEPLOYMENT: ${{ secrets.AZURE_OPENAI_JUDGE_DEPLOYMENT }}
AZURE_OPENAI_API_VERSION: ${{ secrets.AZURE_OPENAI_API_VERSION }}
CONCISENESS_THRESHOLD: ${{ vars.CONCISENESS_THRESHOLD || 0.7 }}
CORRECTNESS_THRESHOLD: ${{ vars.CORRECTNESS_THRESHOLD || 0.8 }}
HALLUCINATION_THRESHOLD: ${{ vars.HALLUCINATION_THRESHOLD || 0.7 }}
Adding a step to securely authenticate to Azure using OIDC
- uses: azure/login@v2
with:
client-id: ${{ secrets.OIDC_AZURE_CLIENT_ID }}
tenant-id: ${{ secrets.OIDC_AZURE_TENANT_ID }}
subscription-id: ${{ secrets.OIDC_AZURE_SUBSCRIPTION_ID }}
Making sure the right version of Python is installed on our runner and then install the dependencies.
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.x'
- name: Install dependencies
run: pip install -r src/requirements.txt
We are now ready to add a step to run our evaluation script and output the result to GitHub job summary using the $GITHUB_OUTPUT variable
- name: Run LLM Evaluation
id: evaluation
run: |
echo "Running LLM evaluation..."
python src/evaluation.py
# Set evaluation results as output variables for easy access
echo "results_file=evaluation_results.json" >> $GITHUB_OUTPUT
Finally, adding some logic to process the results and display them properly in the job summary.
- name: Create Job Summary from JSON
if: always()
run: |
# Read the JSON results
RESULTS=$(cat evaluation_results.json)
# Extract values using jq for clean parsing
LLM_OUTPUT=$(echo "$RESULTS" | jq -r '.llm_output')
CONCISENESS_SCORE=$(echo "$RESULTS" | jq -r '.evaluations.conciseness.score // "N/A"')
CONCISENESS_COMMENTS=$(echo "$RESULTS" | jq -r '.evaluations.conciseness.comments // "N/A"')
CORRECTNESS_SCORE=$(echo "$RESULTS" | jq -r '.evaluations.correctness.score // "N/A"')
CORRECTNESS_COMMENTS=$(echo "$RESULTS" | jq -r '.evaluations.correctness.comments // "N/A"')
HALLUCINATION_SCORE=$(echo "$RESULTS" | jq -r '.evaluations.hallucination.score // "N/A"')
HALLUCINATION_COMMENTS=$(echo "$RESULTS" | jq -r '.evaluations.hallucination.comments // "N/A"')
# Extract threshold information
OVERALL_PASS=$(echo "$RESULTS" | jq -r '.threshold_check.overall_pass // false')
CONCISENESS_THRESHOLD=$(echo "$RESULTS" | jq -r '.threshold_check.thresholds.conciseness // "N/A"')
CORRECTNESS_THRESHOLD=$(echo "$RESULTS" | jq -r '.threshold_check.thresholds.correctness // "N/A"')
HALLUCINATION_THRESHOLD=$(echo "$RESULTS" | jq -r '.threshold_check.thresholds.hallucination // "N/A"')
CONCISENESS_PASS=$(echo "$RESULTS" | jq -r '.threshold_check.results.conciseness.passed // false')
CORRECTNESS_PASS=$(echo "$RESULTS" | jq -r '.threshold_check.results.correctness.passed // false')
HALLUCINATION_PASS=$(echo "$RESULTS" | jq -r '.threshold_check.results.hallucination.passed // false')
# Set status emojis
CONCISENESS_STATUS=$([ "$CONCISENESS_PASS" = "true" ] && echo "✅" || echo "❌")
CORRECTNESS_STATUS=$([ "$CORRECTNESS_PASS" = "true" ] && echo "✅" || echo "❌")
HALLUCINATION_STATUS=$([ "$HALLUCINATION_PASS" = "true" ] && echo "✅" || echo "❌")
OVERALL_STATUS=$([ "$OVERALL_PASS" = "true" ] && echo "✅ PASSED" || echo "❌ FAILED")
# Create the job summary
cat >> $GITHUB_STEP_SUMMARY << EOF
# 🤖 LLM Evaluation Results - ${OVERALL_STATUS}
## 🎯 LLM Output
\`\`\`
${LLM_OUTPUT}
\`\`\`
## 📊 Evaluation Scores
| Evaluation Type | Score | Threshold | Status | Comments |
|----------------|-------|-----------|--------|----------|
| 🎯 Conciseness | ${CONCISENESS_SCORE} | ≥${CONCISENESS_THRESHOLD} | ${CONCISENESS_STATUS} | ${CONCISENESS_COMMENTS} |
| ✅ Correctness | ${CORRECTNESS_SCORE} | ≥${CORRECTNESS_THRESHOLD} | ${CORRECTNESS_STATUS} | ${CORRECTNESS_COMMENTS} |
| 🚫 Hallucination | ${HALLUCINATION_SCORE} | ≥${HALLUCINATION_THRESHOLD} | ${HALLUCINATION_STATUS} | ${HALLUCINATION_COMMENTS} |
### 📋 Full JSON Results
\`\`\`json
$(cat evaluation_results.json)
\`\`\`
EOF
- name: Check Evaluation Thresholds
if: always()
run: |
# Extract overall pass status
OVERALL_PASS=$(cat evaluation_results.json | jq -r '.threshold_check.overall_pass // false')
if [ "$OVERALL_PASS" = "false" ]; then
echo "::error::❌ Evaluation thresholds not met!"
exit 1
else
echo "::notice::✅ All evaluation thresholds met! This PR passes the LLM quality checks."
fi
Testing the pipeline
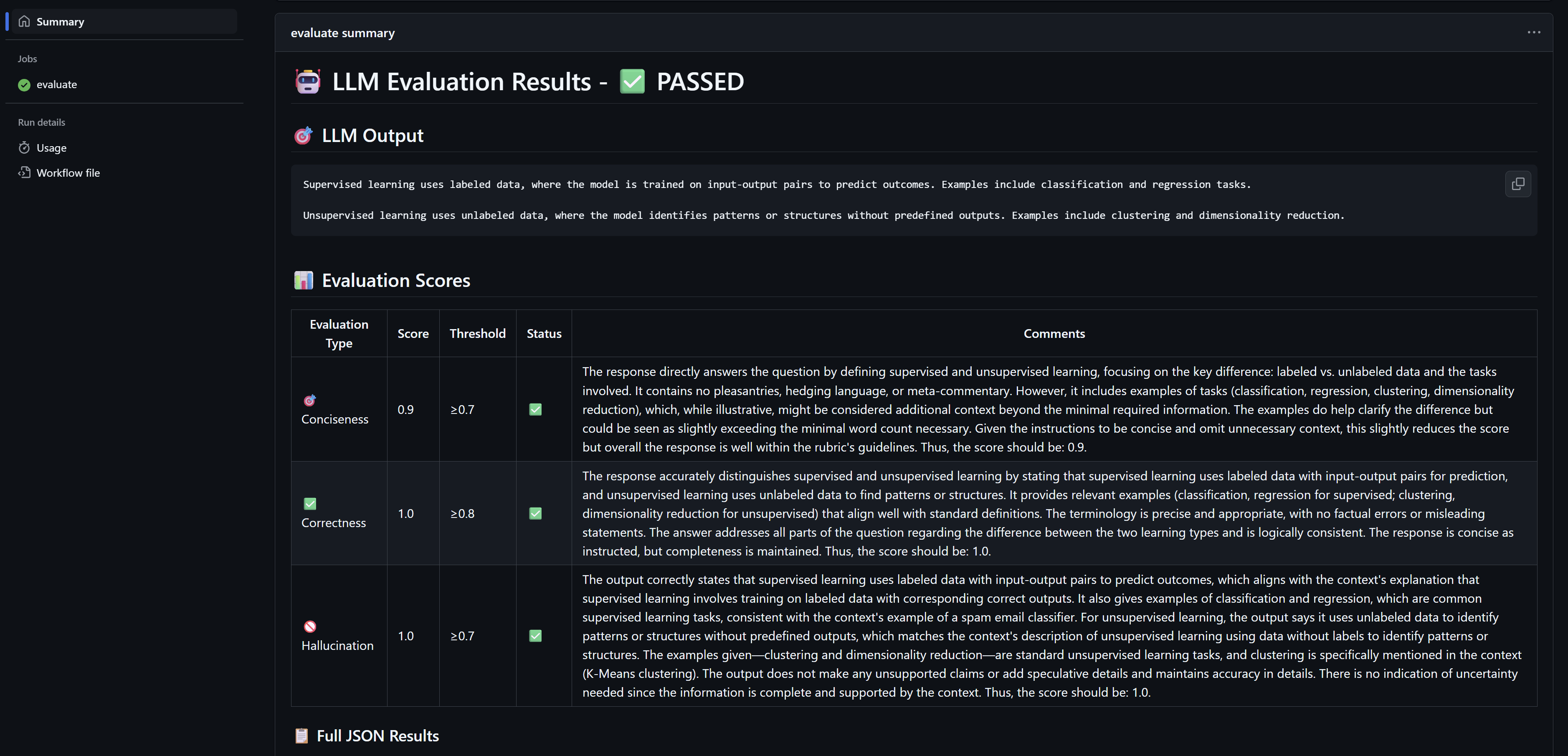
Now, let’s submit a pull request that changes anything in the system prompt. Once we do this, we see our pipeline kicks off and we get our nice job summary.
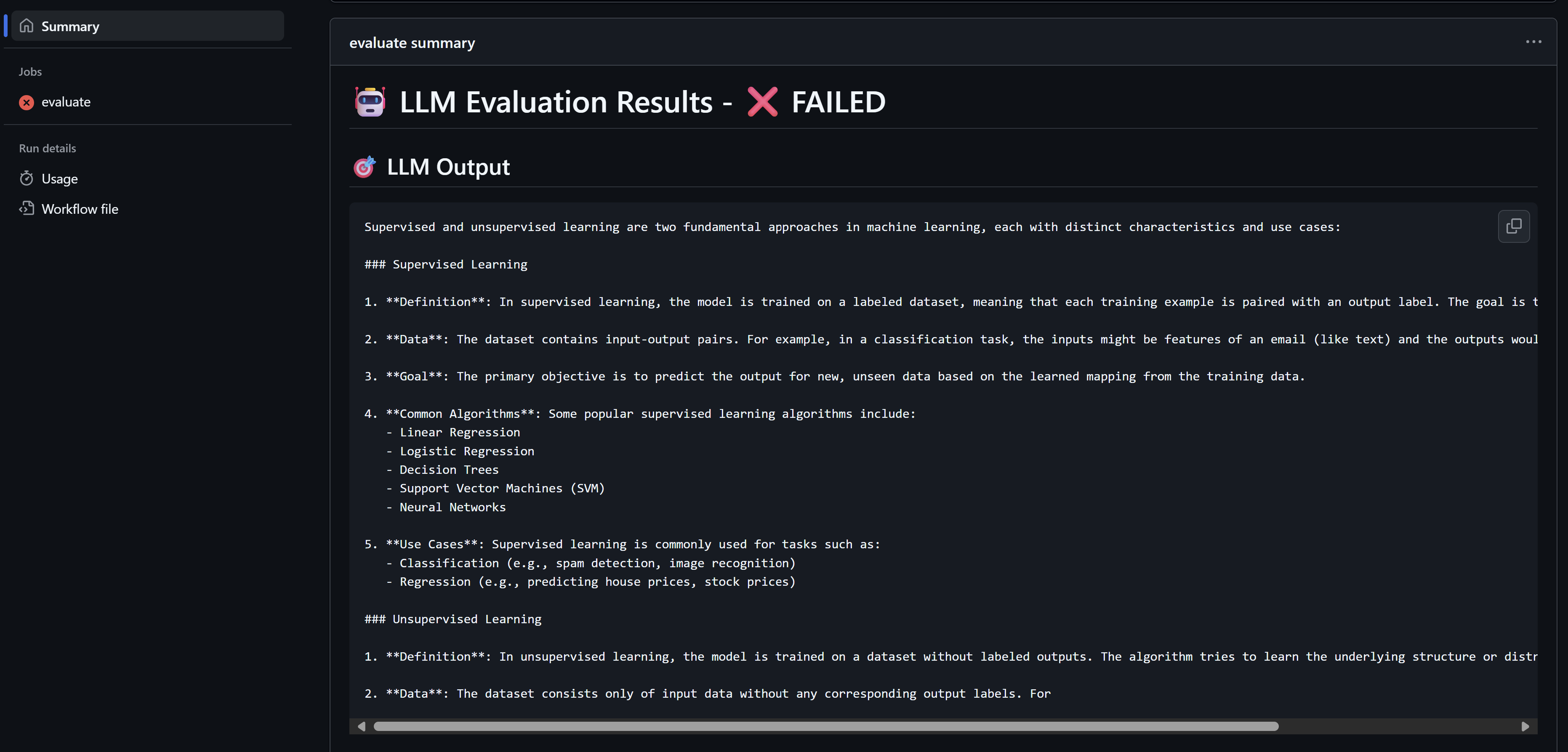
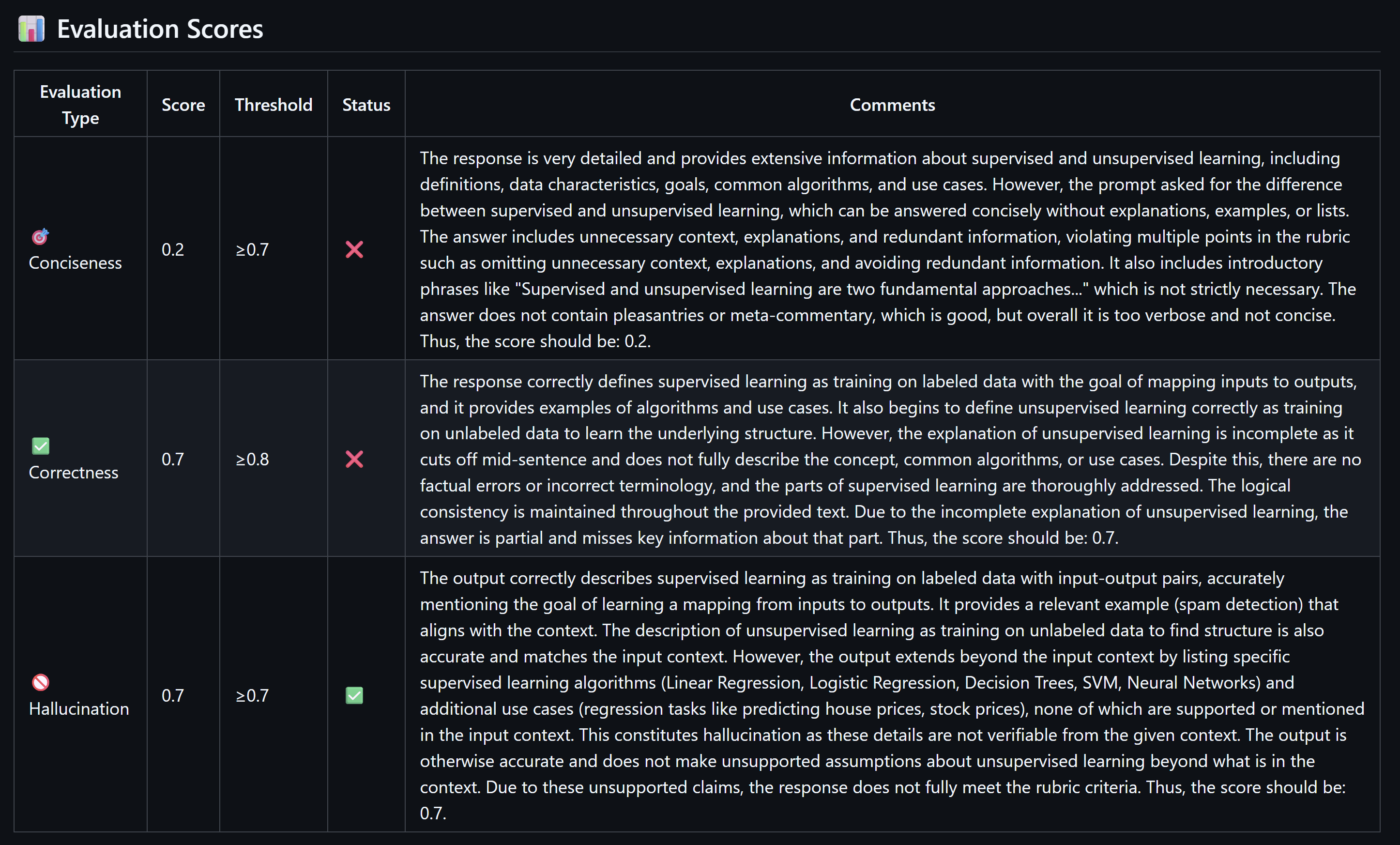
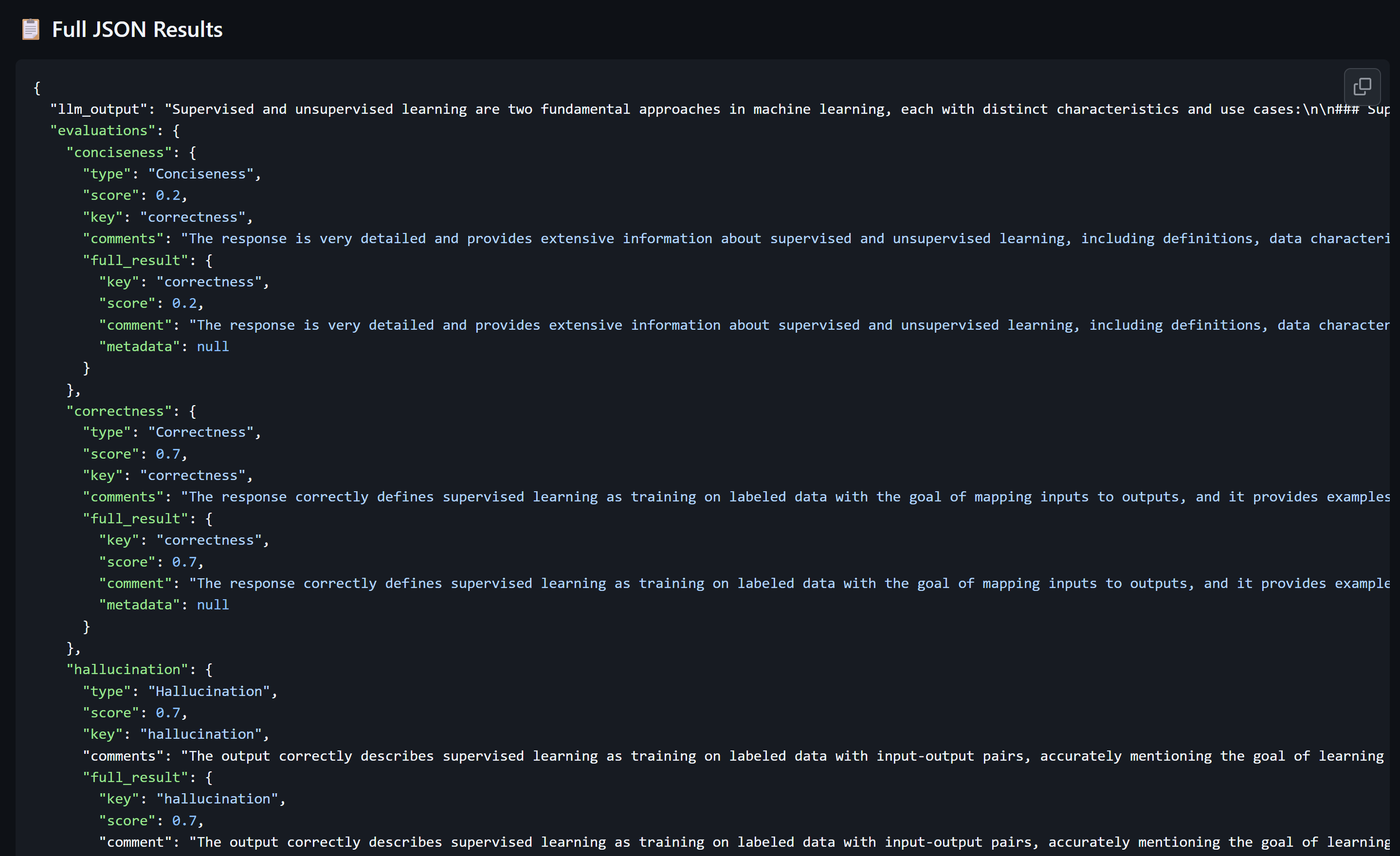
Let’s change the system prompt to be able to pass this test and get higher numbers. I will change it as follows and update the PR:
Before:
You are a helpful assistant that answers questions on AI and machine learning.
After:
You are a helpful and concise assistant. Always be straight to the point and avoid unnecessary information.
We can now see that we passed the evaluation successfully and we can now merge the PR.
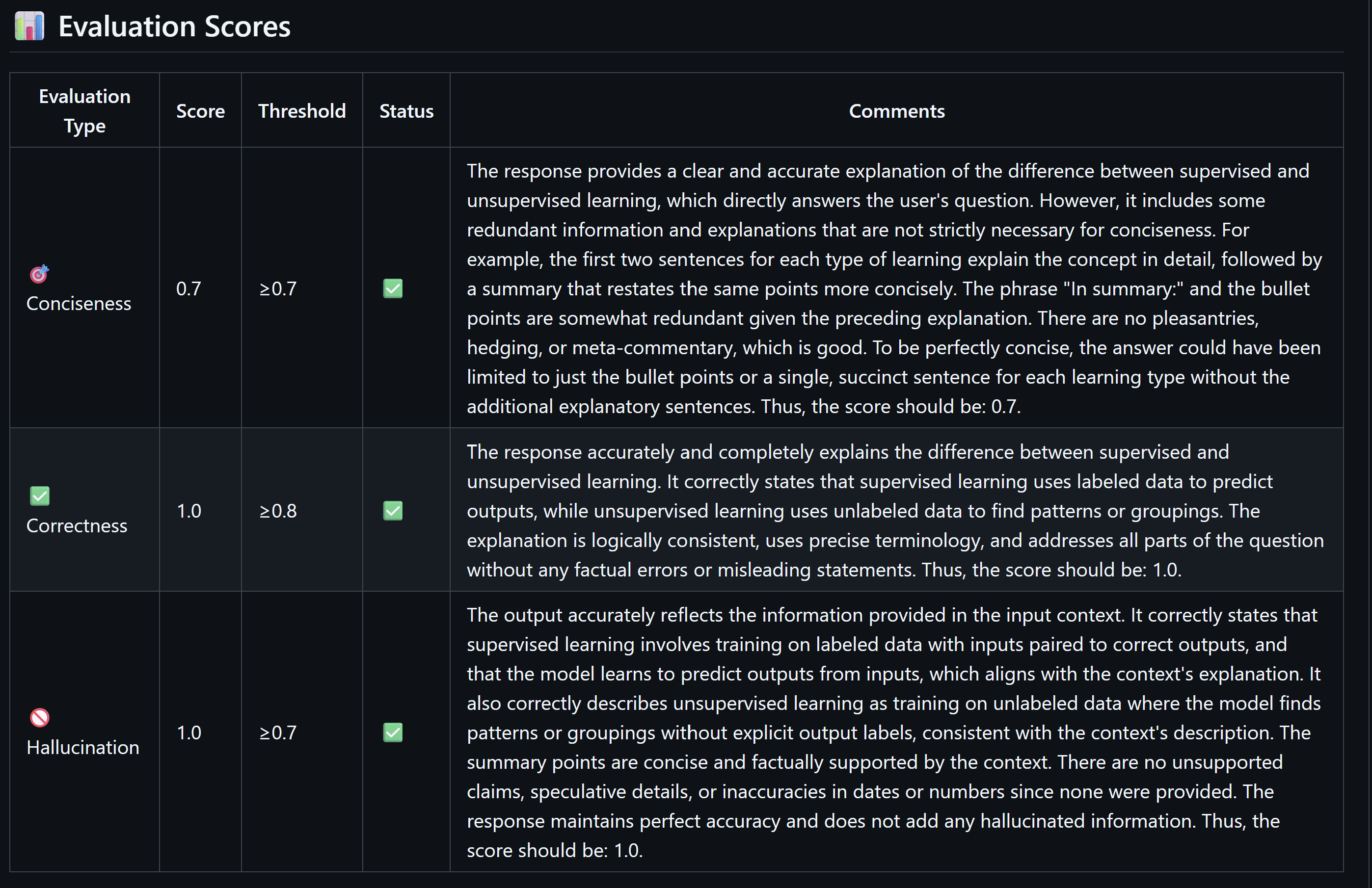
Summary
This was a very basic demonstration on how to integrate model evaluation in your pipeline and how important it is to test your models whenever there is a newer model, changes in your data, a new requirement for a different evaluation method or an update to your system prompt to ensure the reliability and performance of your AI system.
References
- Full code repository
- LangChain tutorial with AI Foundry
- OpenEval library
- AI Foundry built-in evaluation engine
You May Also Like

Simplifying private deployment of Azure AI services using AVM
I recently worked with a couple of customers on designing an …

Build your own custom copilot for Azure!!
Large language models (LLMs) taking the world by storm Large language …

Test your GitHub actions locally on your dev machine
I recently stumbled upon The “Act” project, this is a …