
Azure Chaos Studio - Wreak Chaos in your Azure environment
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production. Sometimes, we think our system is perfectly architected and is highly available, but only in the midst of an actual incident where we start to see the shortcomings and re-think our architecture.
“All great changes are preceded by chaos” - Deepak Chopra
Azure Chaos studio is new service in Azure that allows you to systematically inject failures in your system to understand how it will react in case of an actual disaster whether it’s a more than usual load, service or region failure, network problem ,…etc. In this post, I will give this new solution a try to inject failures in my system, observe it’s state and finally introduce some enhancements based on the results.
Initial system Architecture
I’m running a sample e-commerce website on an AKS cluster with the following components:
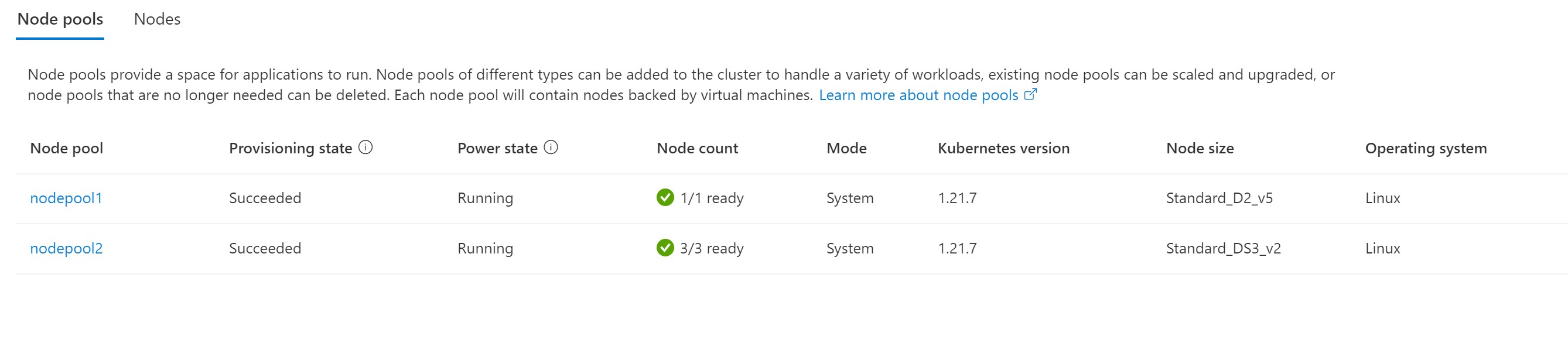
- One node pool that is backed by a Virtual Machine Scale set.
- An nginx ingress service
- No auto-scaling of pods is enabled
Using Azure Chaos Studio to fail my e-commerce site
The service consists of two main steps, on-boarding an Azure service and creating experiments. Some services support agent-based faults (like CPU pressure, I/O stress, kill process, ..etc) and some support service-based faults (like VMSS shutdown, Cosmos DB failover,. ..etc) and some services support both types of faults.
In this demonstration, I will attemp to fail my system by doing the following:
- Inject an AKS service mesh CPU stress on my front-end Nginx service, this should simulate having a huge number of requests on the frontend and eventually should fail my system if it’s not ready to scale.
- Force shutdown the Virtual Machine Scale Set (VMSS) instance running my single node pool, this should cause my whole AKS system to be down due to having only one node pool.
Onboarding services
The first step, is to onboard our AKS cluster and VMSS TO Azure Chaos Studio. AKS supports only service-based faults and VMSS supports both but in our experiment of shutting down the VMSS instance, we will need only the service-based fault.
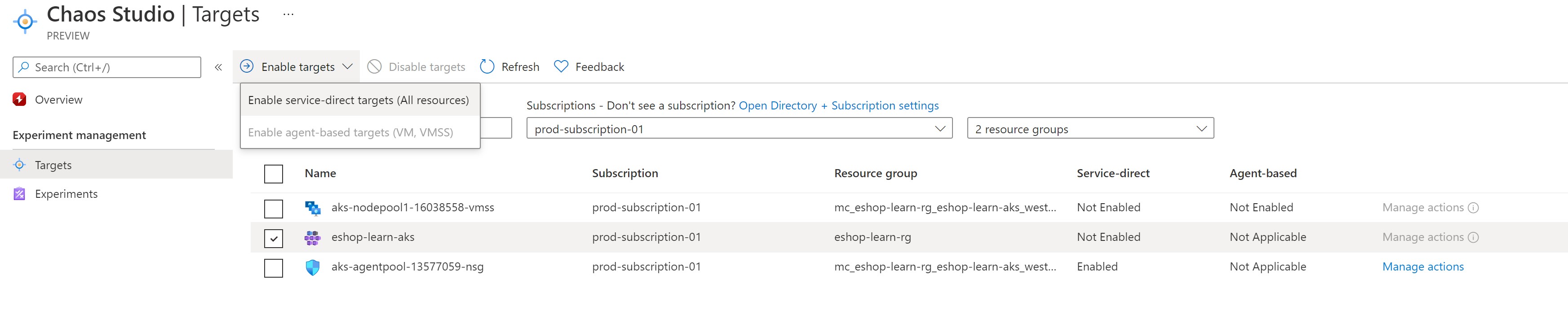
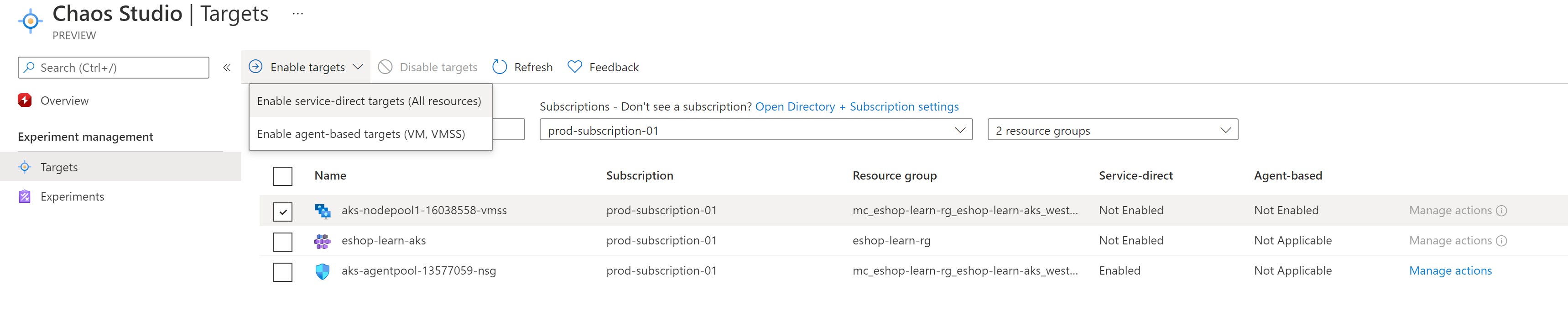
Next, we need to create an experiment to define the faults we need to inject. Experiments allow you to create multiple steps that run in sequence and within each step, you can create branches that run in-parallel within a single step.
Our first step would be injecting a CPU stress in our AKS cluster that targets our frontend Nginx service. Azure Chaos studio leverages the open source cloud-native Chaos engineering platform Chaos Mesh to inject it’s AKS-related faults. This would require installing the service onto our AKS cluster.
az aks get-credentials -g eshop-learn-rg -n eshop-learn-aks
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm repo update
kubectl create ns chaos-testing
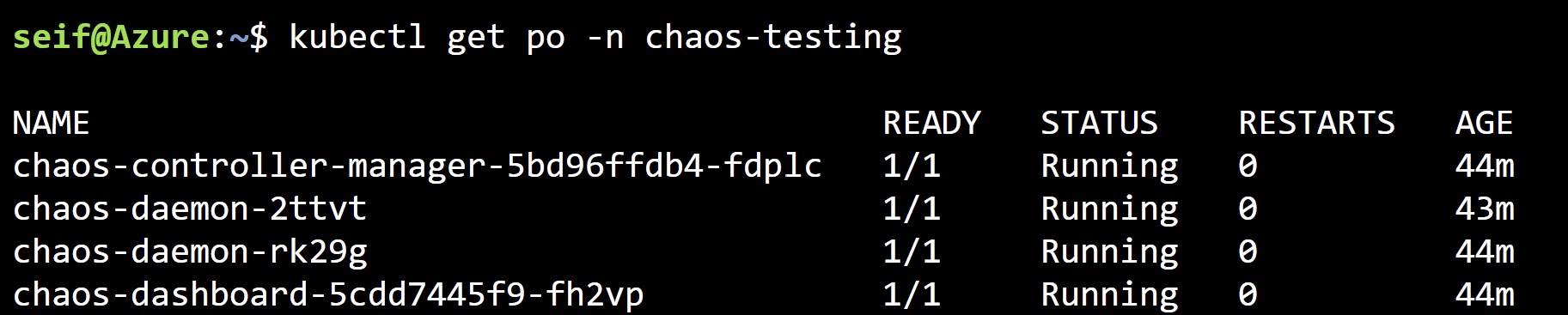
helm install chaos-mesh chaos-mesh/chaos-mesh --namespace=chaos-testing --version 2.0.3 --set chaosDaemon.runtime=containerd --set chaosDaemon.socketPath=/run/containerd/containerd.sock
We can now see that the Chaos Mesh pods are indeed deployed and running on our AKS cluster.
Creating the experiment
Now, let’s create the first step of a 95% CPU stress that would run for 3 minutes and targets just one of the pods in the ingress-nginx namespace. We would need to use the syntax of the Chaos Mesh service but convert it into JSON instead of YAML.
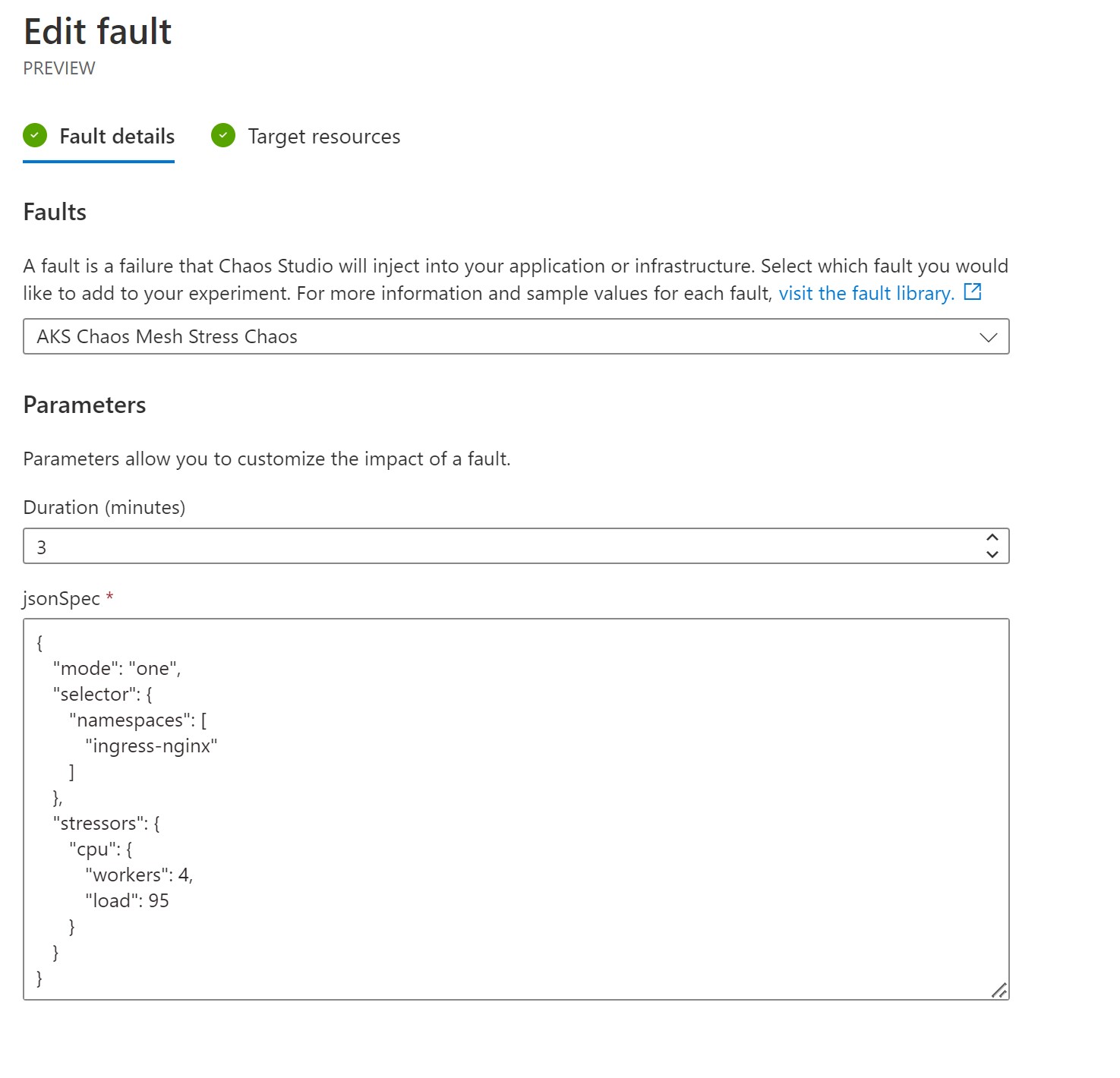
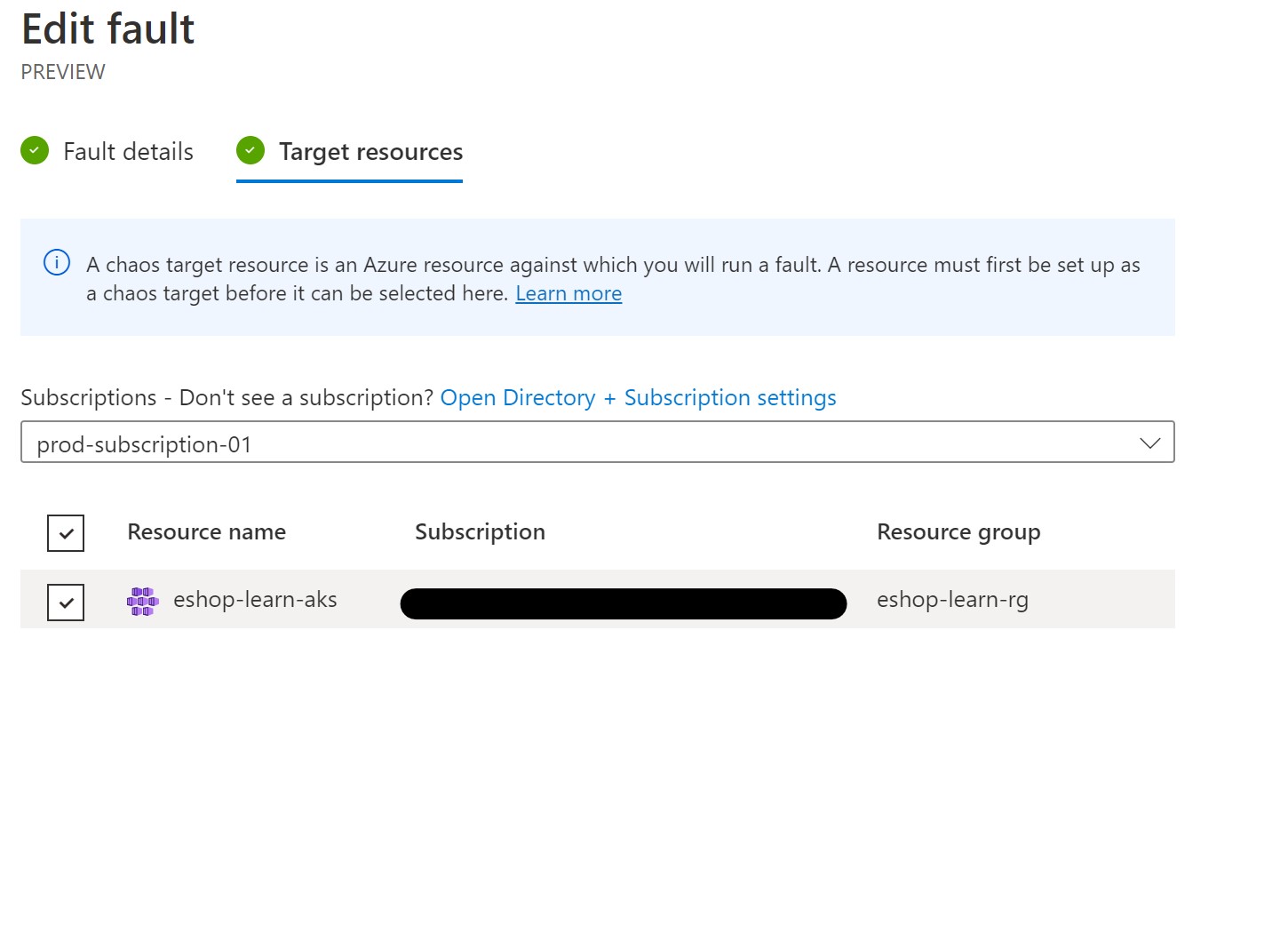
This is how our firs step looks like.
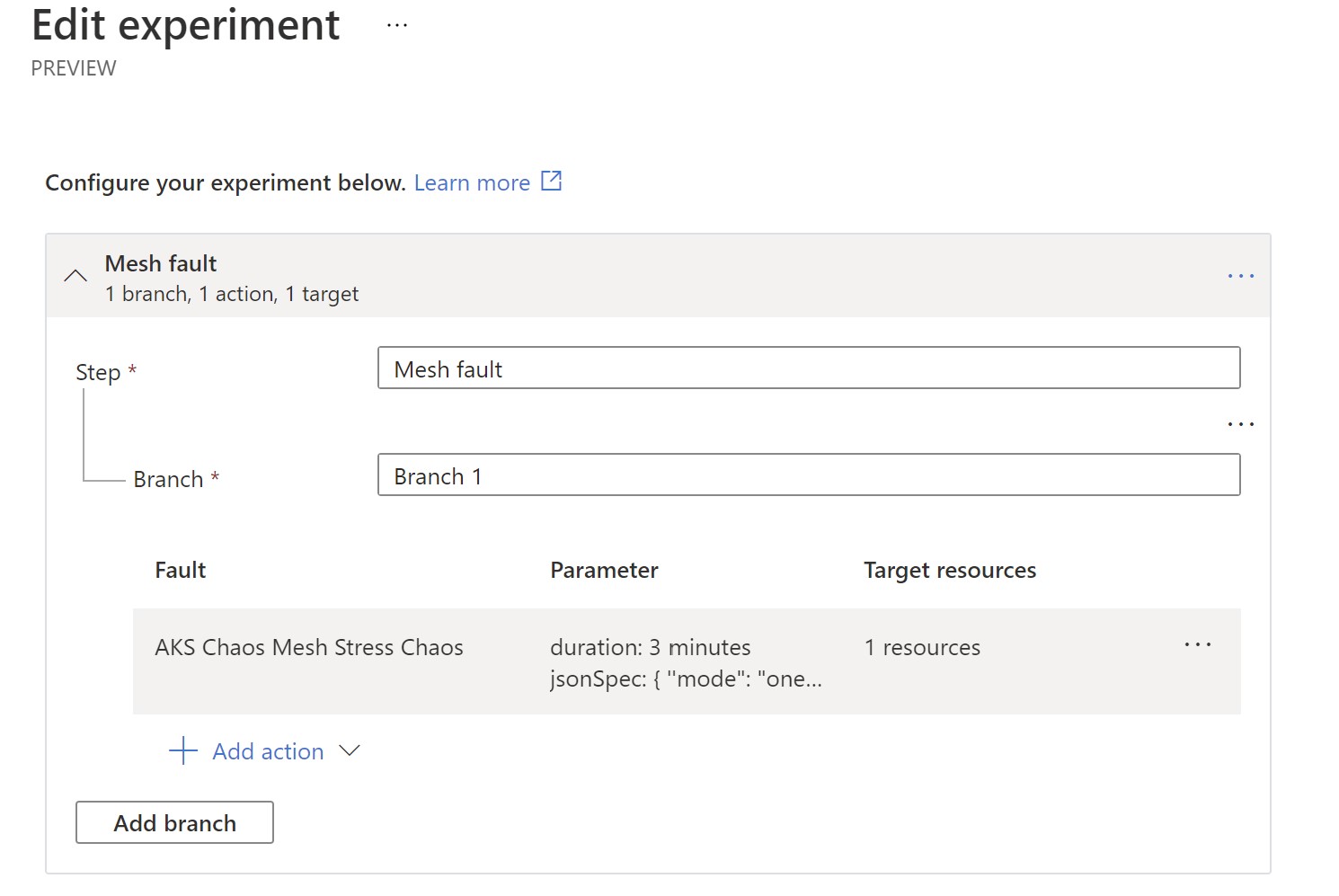
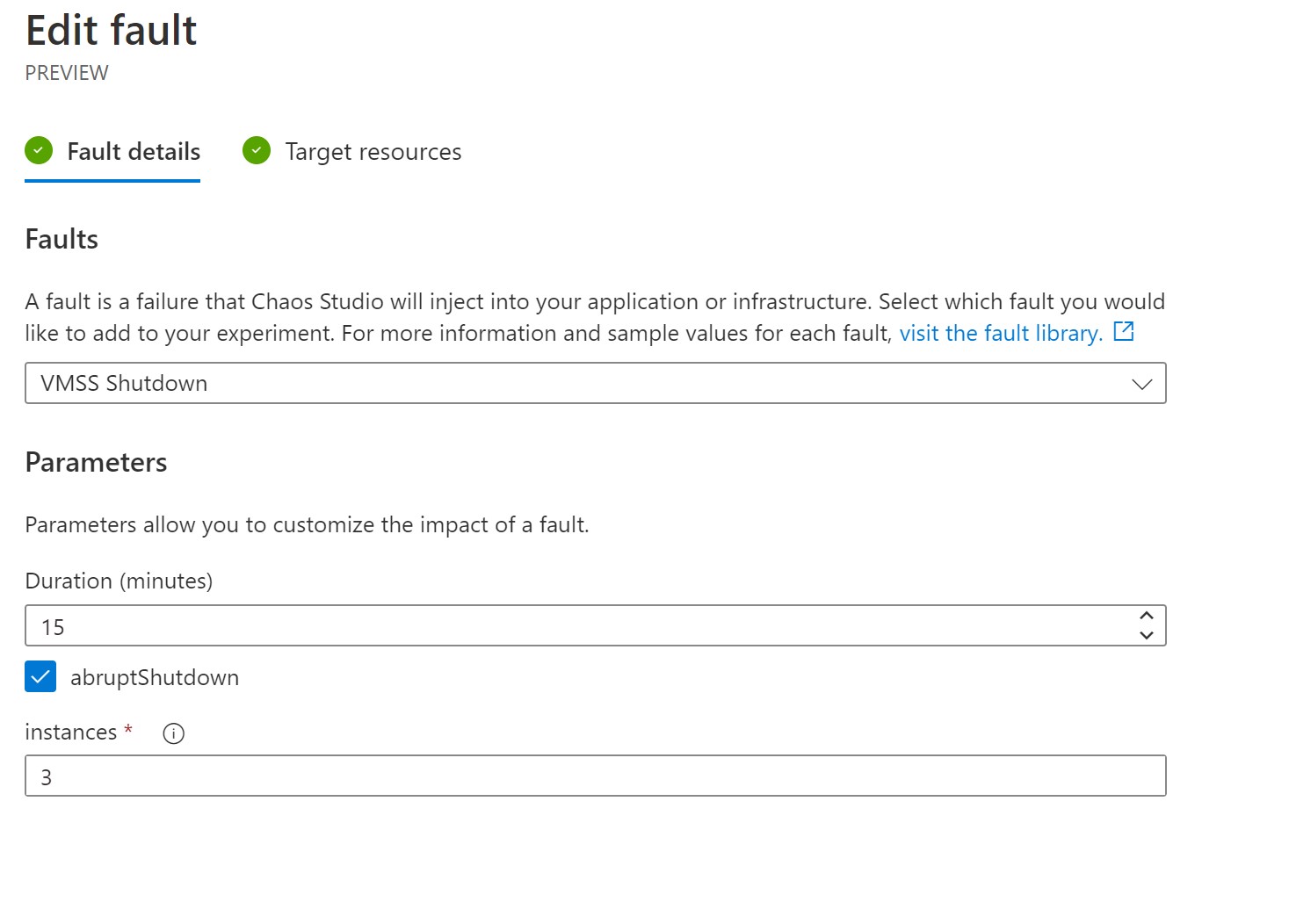
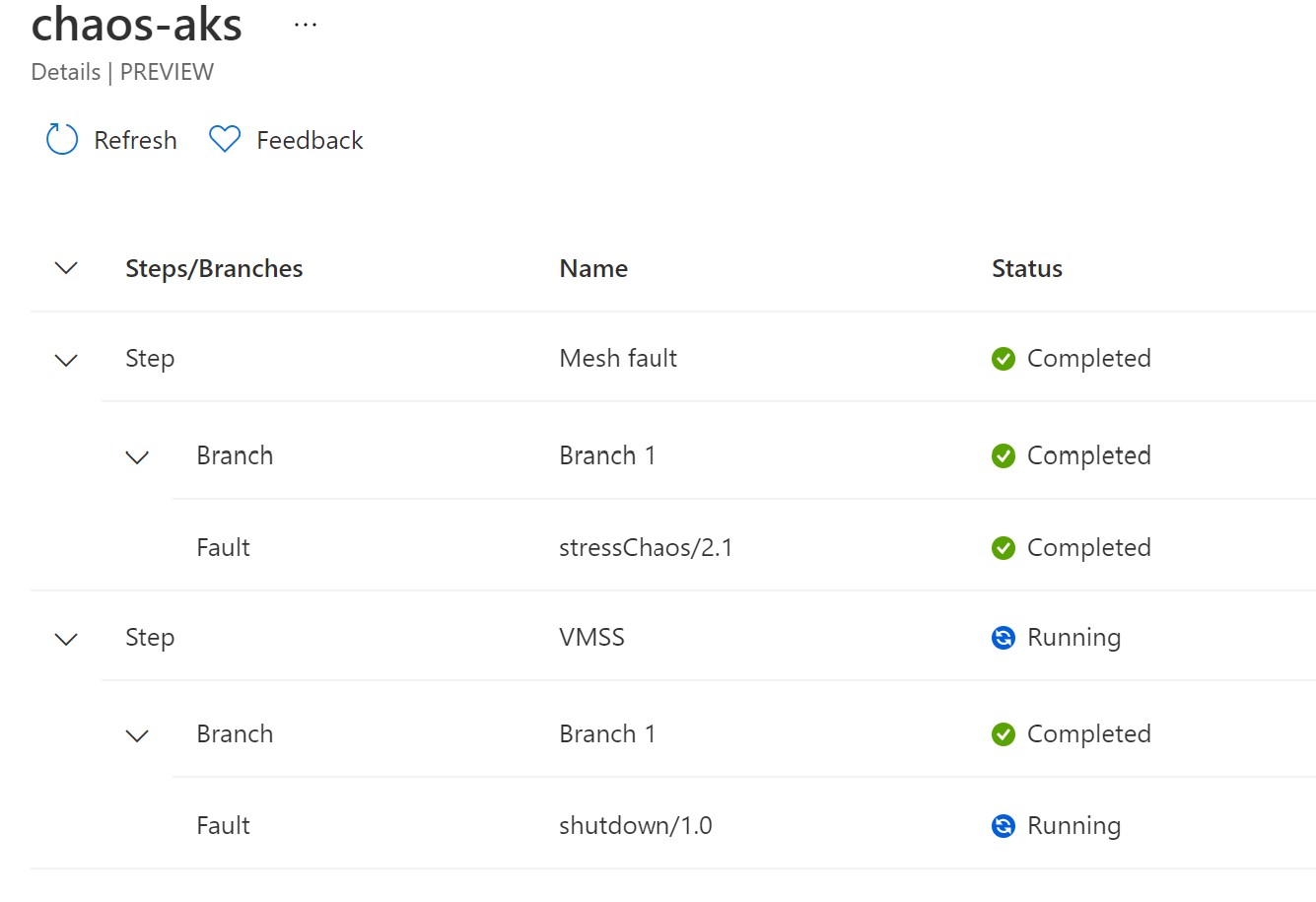
Next, we will add an additional step to shutdown our VMSS-backed node pool for 15 minutes and select the instance ID of our only instance running withing this VMSS.
Now, we have an experiment ready with two steps.
Before running our experiment, we need to grant it the necessary RBAC permission to be able to inject it’s faults. For the AKS step, it needs to have Azure Kubernetes Cluster Admin role on the AKS cluster and for the VMSS step, it needs to have Virtual Machine Contributor role on the VMSS instance.
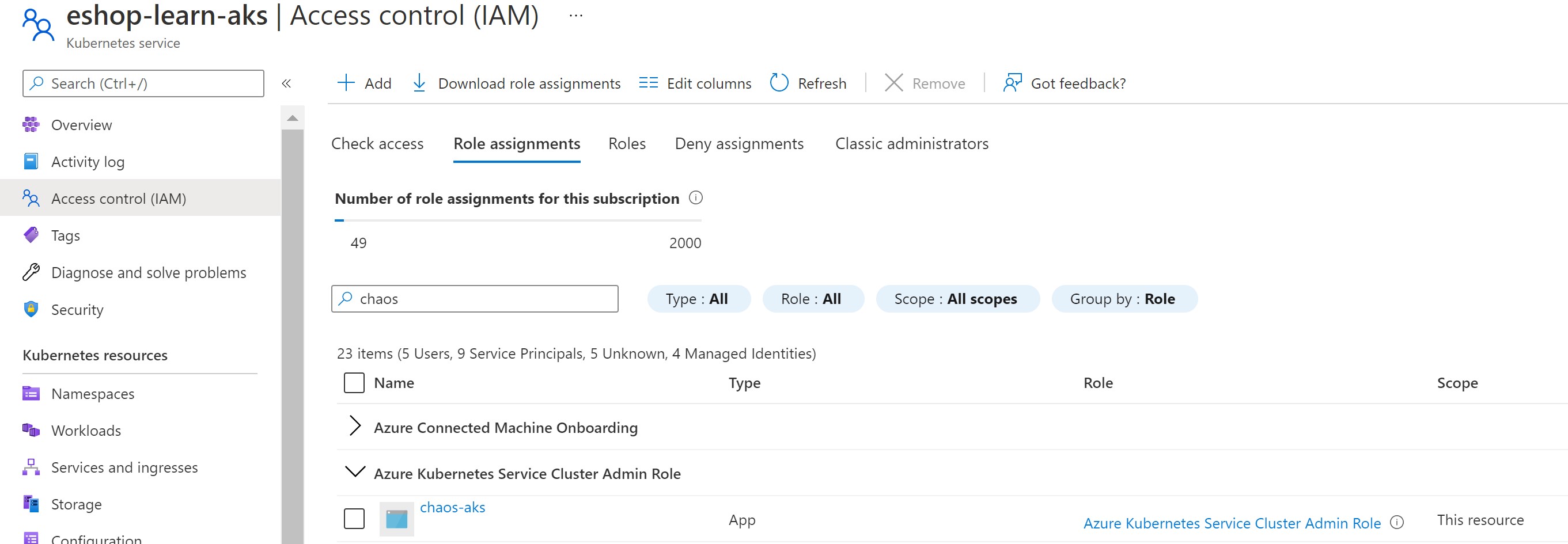
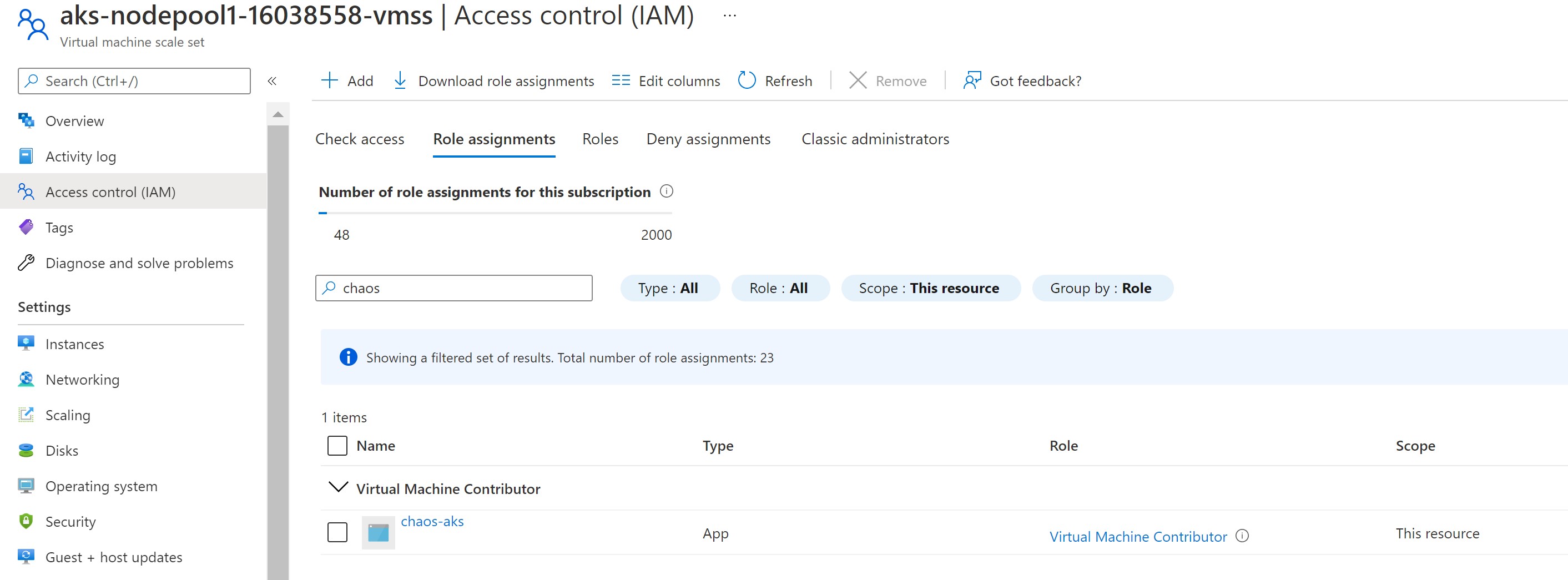
Testing our system
After having everything ready , let’s start to run the experiment and see how our system holds up.

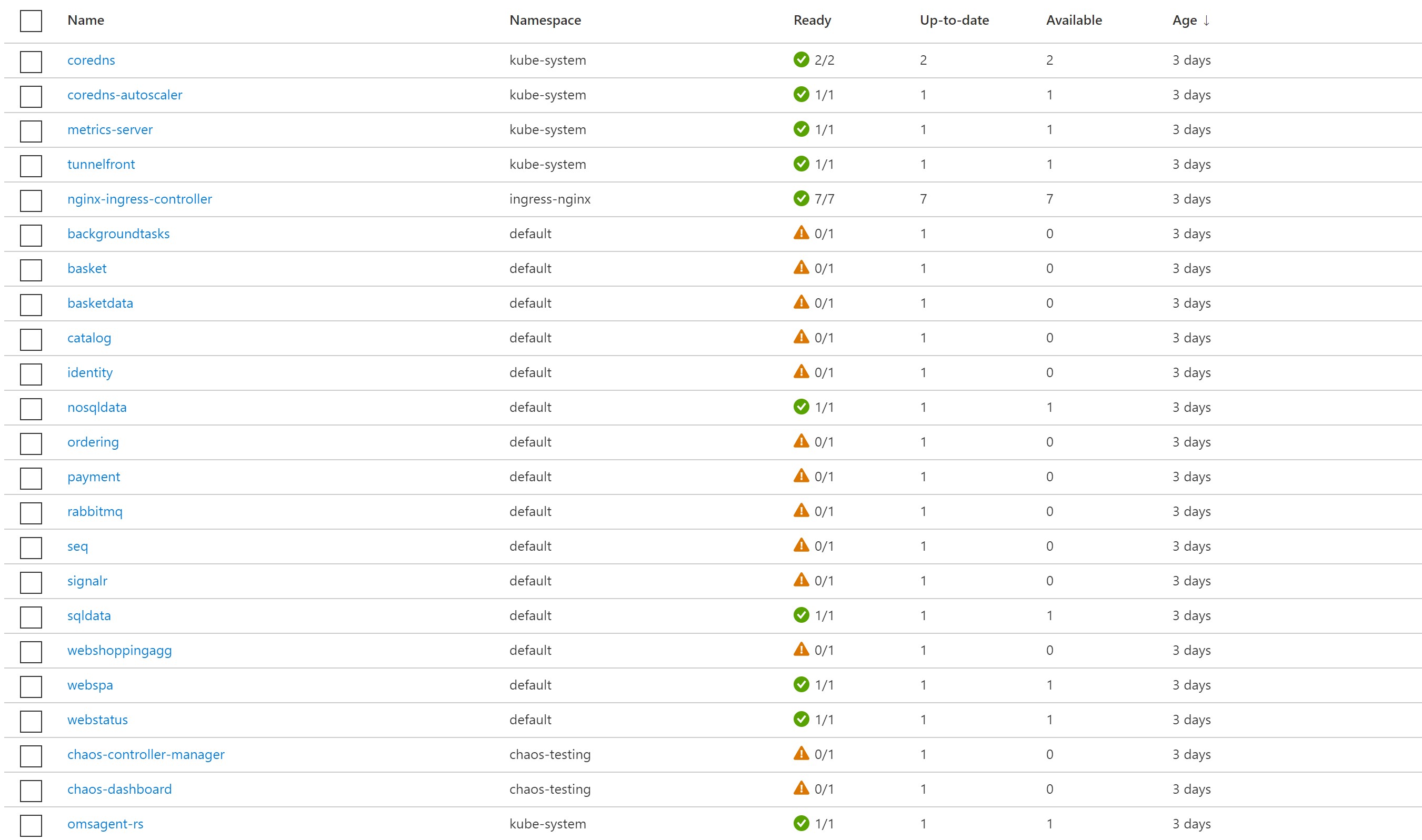
The first step would cause 95% CPU stress on our frontend. Looking at the AKS insights, we can see that our nginx pods are under so much CPU stress and since we haven’t setup any scaling, eventually our website goes down.


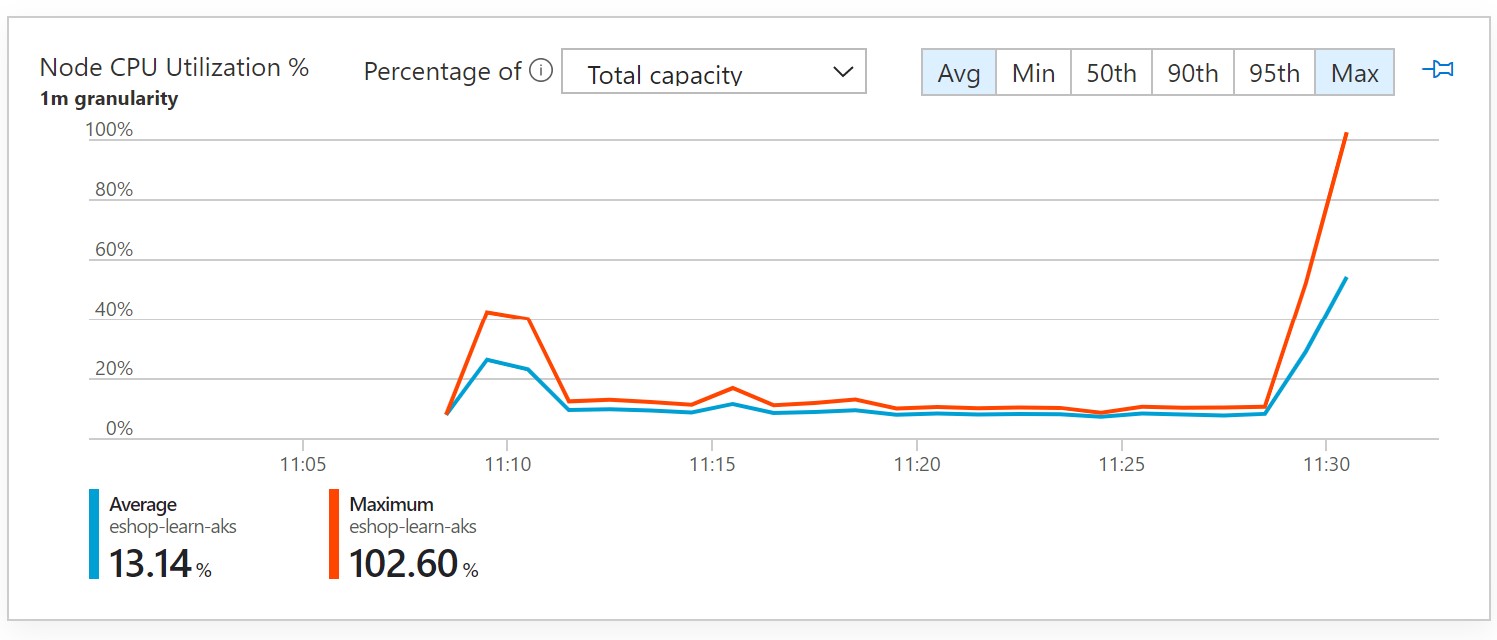
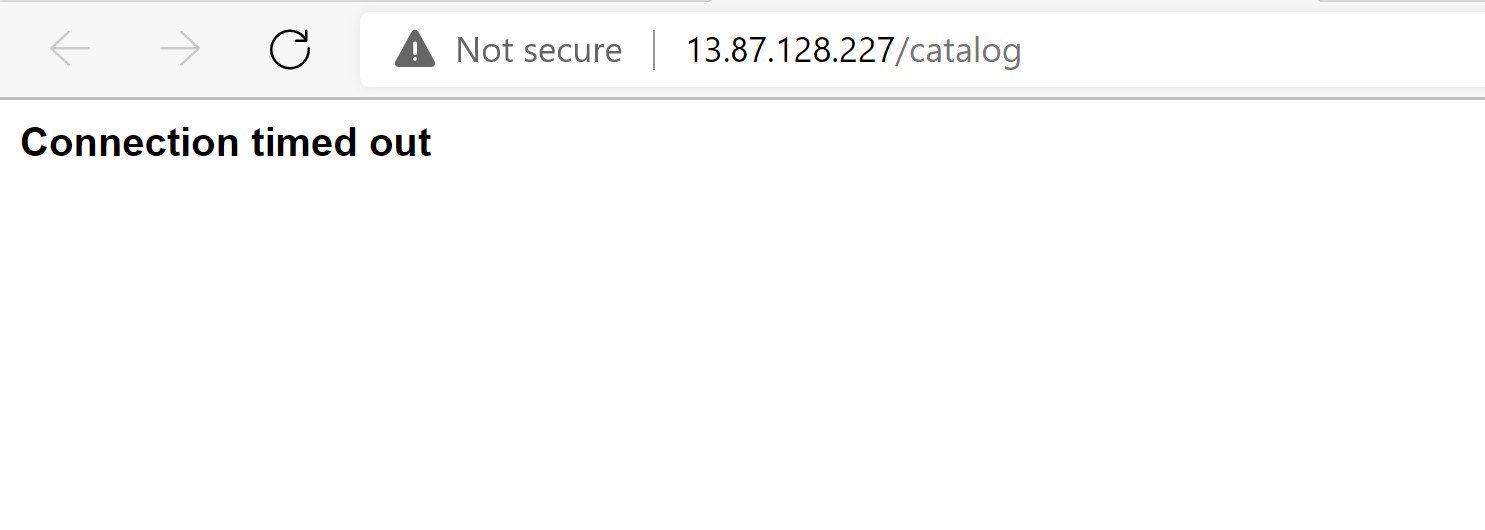
After 3 minutes have passed, it is time for our VMSS shutdown step.
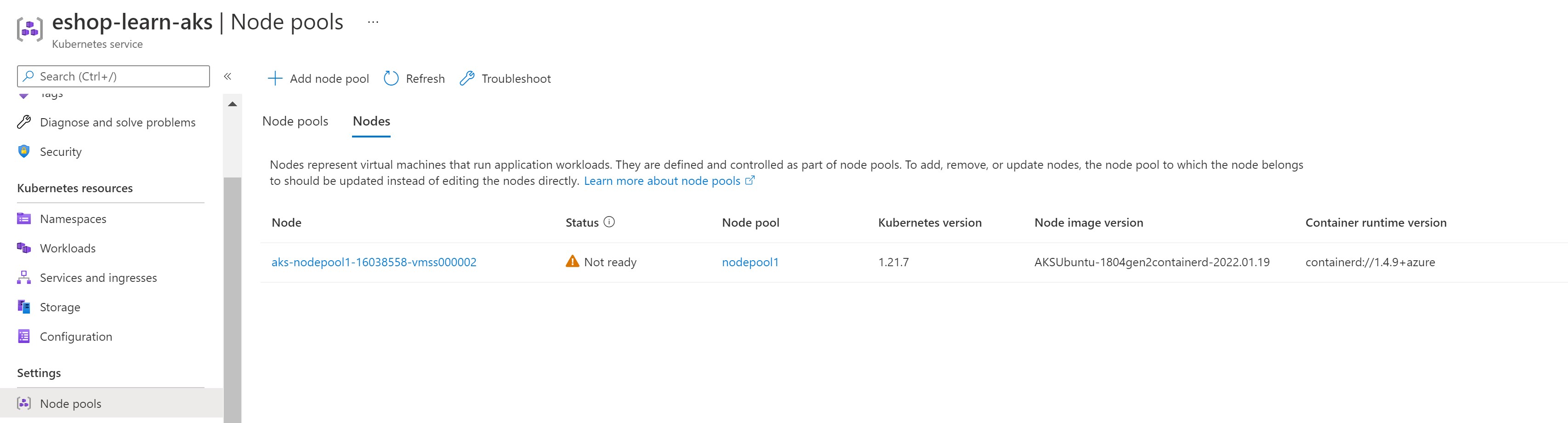
Our main and only node pool has been indeed shutdown and all pods are not running and of course, our website goes down.
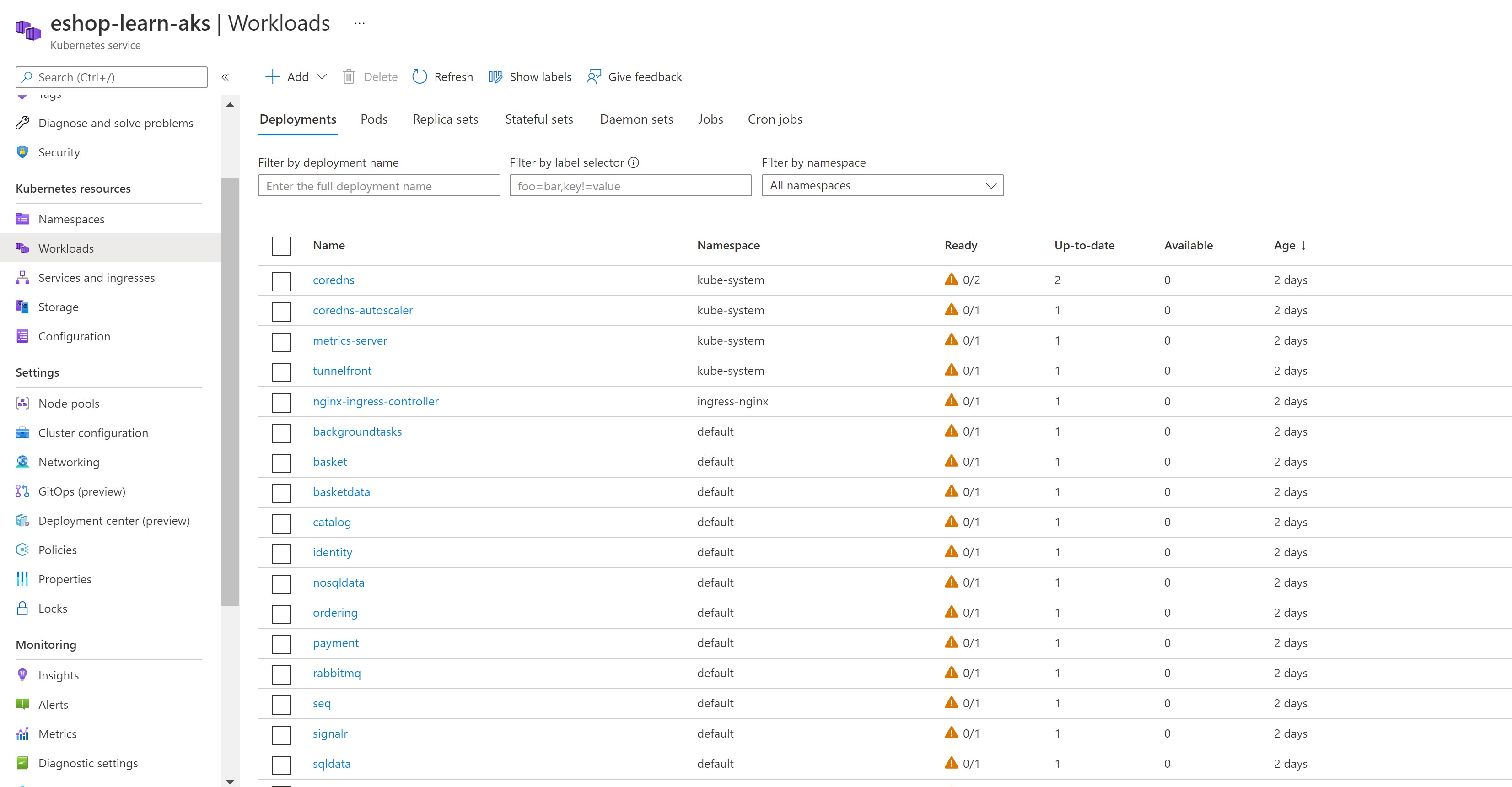
Learning from the experiment
This experiment has shown us that our system is not resilient and more work needs to be done to have it production-ready. In this next attempt, I will add an additional node pool and enabled the horizontal pod scaler and re-run the experiment again.
Adding an additional node pool.
Enabling the horizontal pod scaler for our frontend nginx service to scale up between 3-10 pods on 50% CPU stress.

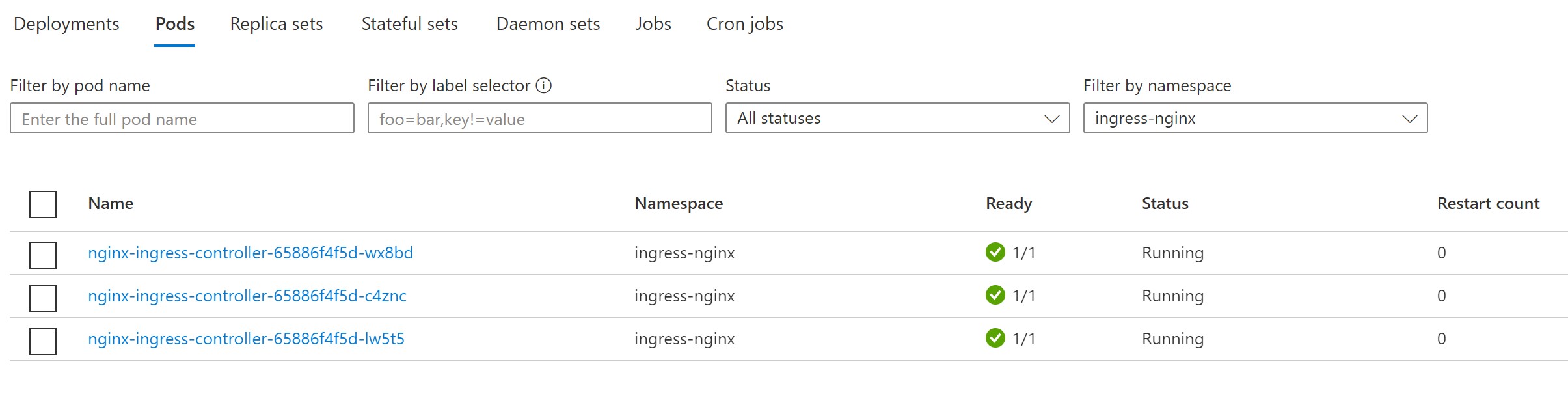
Re-running the experiment, we first see our frontend pods under the same pressure, but this time they scale up to 10 pods instead of failing immediately.

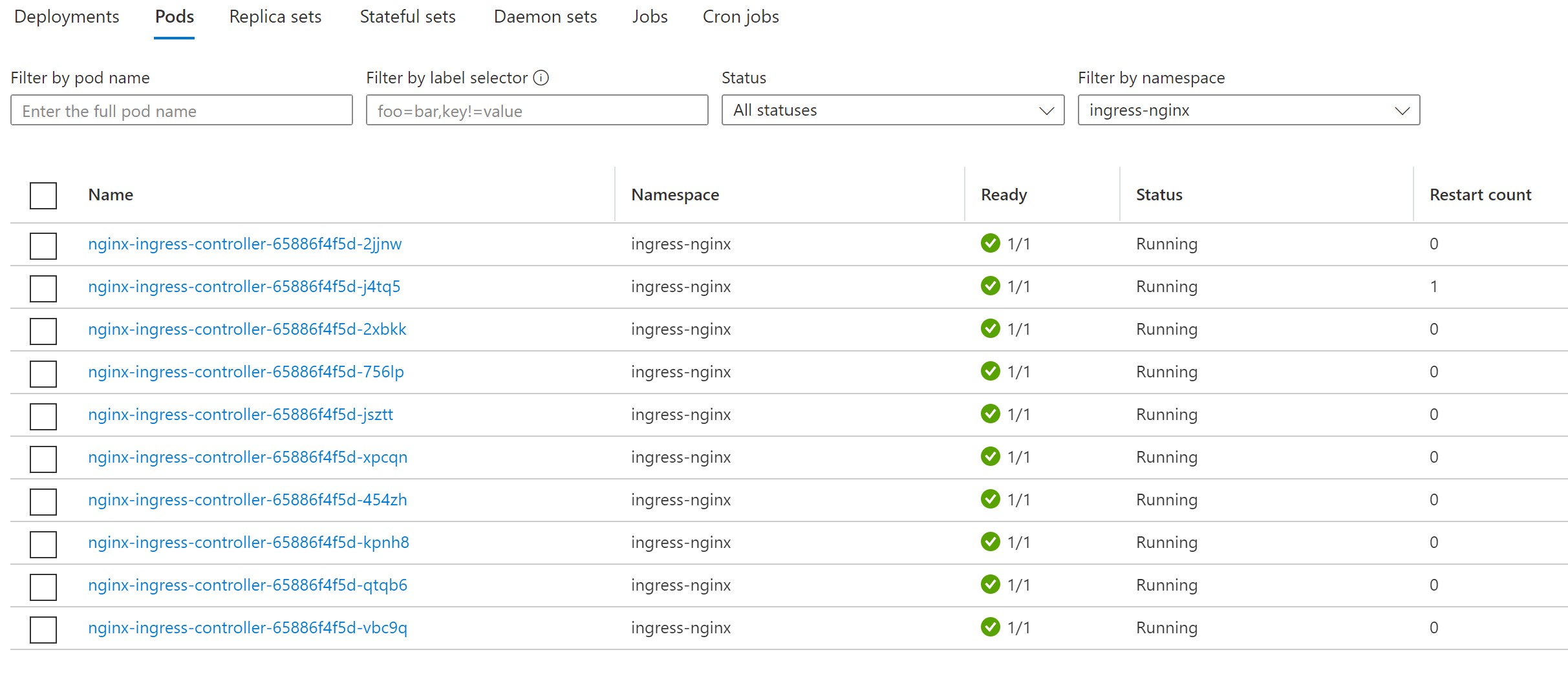
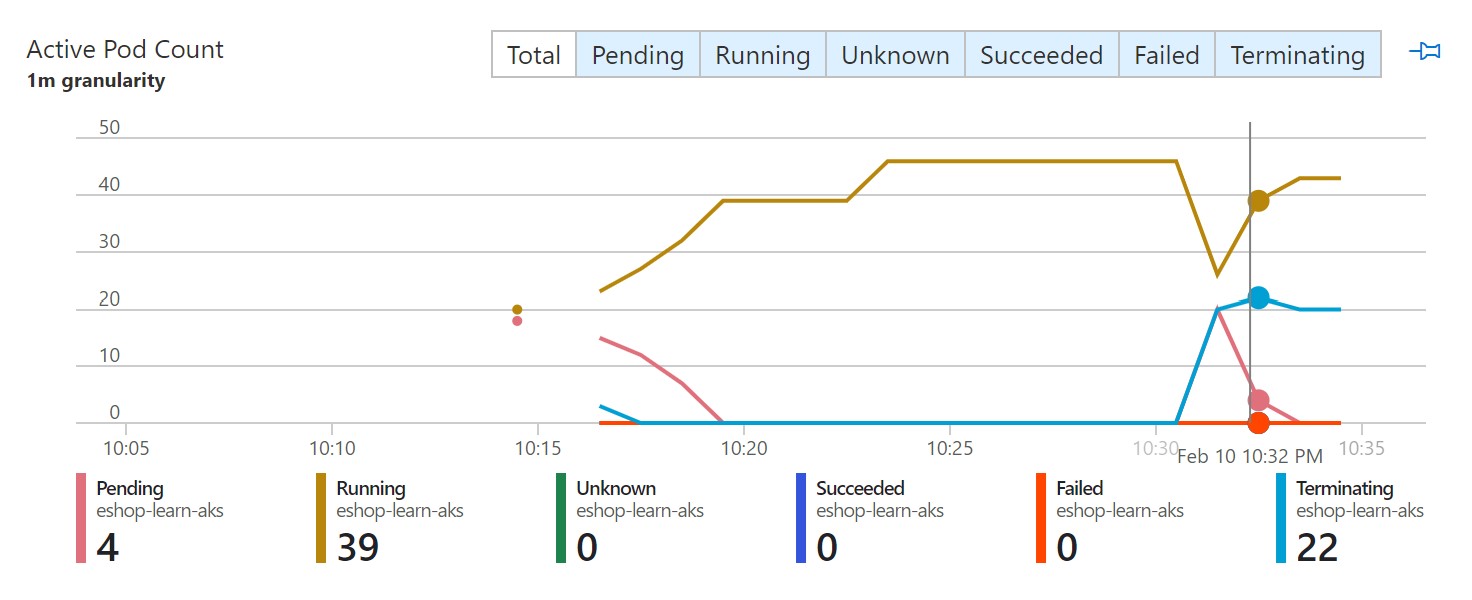
Our website keeps running instead of going down in this case.
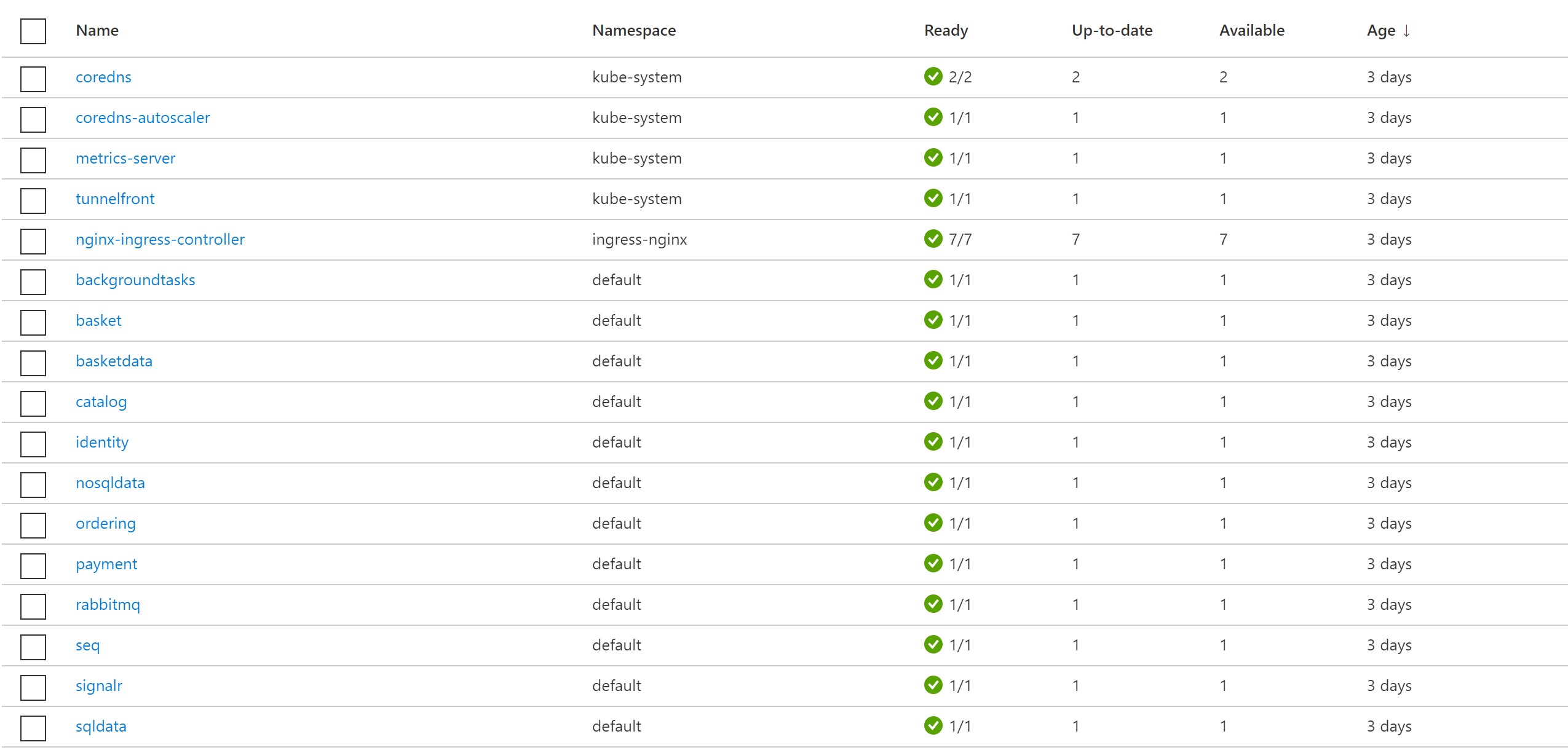
After 3 minutes when it’s time for our VMSS shutdown step, we can see that the first node pool shutdowns down but we now have an additional one for more resiliency. After some time, the pods start restarting on this node pool and our website continues to run even when one of the node pools goes down.

We can see the pods are now restaring and shorly re-scheduled on the new node pool. Our website comes back up in a matter of minutes.
Summary
Azure Chaos studio is a great tool to help you test your architecture against your high availability and resiliency claims, this form of chaos engineering helps your systems become more fault-proof in cases of real disasters and failures. You can also use it to do performance testing, business continuity drills, understanding the capacity needs of your applications and much more.
Resources
Share on:
My name is
Seif Bassem
You May Also Like
Secure Azure Arc servers onboarding using Conditional Access
One of the most common methods of onboarding servers to Azure Arc is …

Azure Arc Onboarding using Endpoint Configuration Manager
Azure Arc-enabled servers allows you to project your hybrid servers …

Re-usable Bicep modules using Azure Container Registry
Build re-usable Bicep modules Bicep enables you to organize your …